Published 17 years ago
(updated 14 years ago)
Descubriendo y Describiendo Patrones de Datos
Actualmente y desde hace un par de décadas, la cantidad de información que se genera en los medios comerciales, educativos y en general en cualquier sector, se ha incrementado notoriamente. Lo que ha provocado el desarrollo de varias tecnologías enfocadas a aprovechar los datos que se encuentran escondidos en estos grandes volúmenes de información. Algunas de estas tecnologías son por ejemplo los OLAP, Data Warehouse y la Inteligencia de Negocio (Fig. 1), éstas han aportado una considerable mejora en el tratamiento de los datos estructurados y en la mejora de la toma de decisiones. Las bases de datos relacionales (BDR), Data Warehouse (DW), Data Mart (DM), OLAP y OLTP son tecnologías que permiten obtener conclusiones en base a consultas predeterminadas, es decir, son consultas deductivas, realizadas de manera óptima en tiempos cortos y enormes volúmenes de información, conclusiones que serían imposibles de obtener en un proceso manual.Minería de datos
Minería de datos es un concepto que involucra la obtención de conocimiento en forma práctica, no en el sentido teórico. El punto de interés principal, es el de descubrir y describir patrones encontrados en los datos. Pretende resolver problemas o pronosticar nuevos datos a partir de los datos ya presentes que se encuentren en el Data Warehouse corporativo. Por ejemplo: permiten pronosticar la lealtad de un cliente en función de los patrones encontrados en su comportamiento, otro tipo de aplicaciones se encuentran en la predicción de fraudes, fallas de maquinarias, y múltiples aplicaciones orientadas al servicio.

Fig. 1 Tecnologías para el tratamiento de información.

Fig. 2 Aportación de las tecnologías en el tratamiento de información.
Las técnicas de minería de datos al día de hoy se encuentran plenamente desarrolladas, y para algunos tipos de análisis se encuentran en fase de maduración. Los métodos de minería de datos operan sobre datos altamente estructurados (Fig. 3), que se encuentran en repositorios como Data Warehouse o Data Marts, o bien son resultado de aplicar en ellos algún análisis OLAP. Para efectuar la minería es necesario que se realice previamente una preparación sobre los datos, que les provea de la estructura necesaria para la técnica de minería a emplear.

Figura 3. Minería de datos
El proceso de descubrimiento de patrones puede ser automático o semiautomático, los patrones identificados deben ser significativos y aportar alguna ventaja, usualmente de tipo económico.
Aplicación de la minería de datos
Las técnicas empleadas en la minería de datos dependen del tipo de conocimiento que se desee obtener. Existen dos clasificaciones que agrupan los algoritmos de minería, estas son: minería dirigida y no dirigida. Para el primer caso se conoce el tipo de decisión (clase) al que se desea llegar, como por ejemplo: booleano (si /no), tipo, acción.
Las entradas son de tipo numérico o bien de tipo nominal. Los datos numéricos presentan valores talesvv que las comparaciones en rangos tengan sentido, mientras que los datos nominales tienen un significado específico. El dato nominal más común es algo que puede ser clasificado como cierto o falso.
A continuación vamos a realizar un ejemplo de minería dirigida con una muestra de datos referentes a las preferencias de compra de automóviles. La muestra fue recabada dentro de una población reducida de clase media, cuyo centro de trabajo se encuentra en la zona centro de la ciudad. Los tipos de datos son nominales.
La siguiente figura presenta un extracto del conjunto de datos nominales, previamente procesados para realizar la minería.
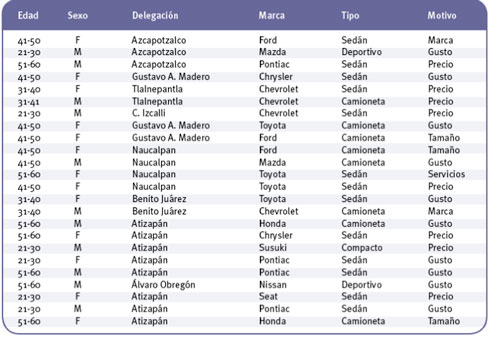
Figura 6. Preferencias en compra de automóviles.
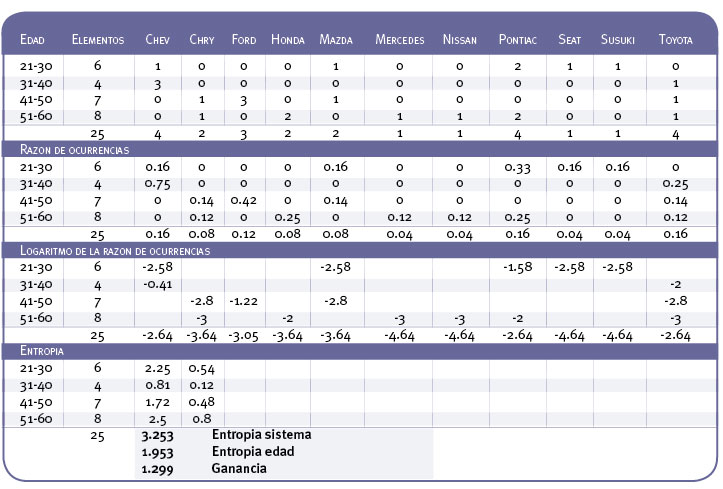
Tabla 1. Cálculo de entropía primer nivel.
El dato que se pretende pronosticar es la marca. Es decir, si se presenta un nuevo individuo a comprar un vehículo, ¿cuál es la marca que podría escoger?
Realicemos la minería paso a paso, con un pequeño subconjunto de los datos anteriores, el método que emplearemos se conoce como ID3, éste es una estrategia que divide y conquista, que opera tratando de maximizar el nivel de ganancia en cada paso. La siguiente tabla contiene el cálculo de la entropía para el atributo edad, se realiza el cálculo de la entropía de cada atributo, la cuál es una medida de la incertidumbre existente en el conjunto de atributos, de los cuales se escoge sólo aquel atributo con mayor ganancia (diferencia entre la entropía del sistema y la entropía del atributo). El atributo seleccionado es el nodo del árbol. Este cálculo se repite desde la selección de la raíz y para cada nivel del árbol.
Calculando las entropías de cada atributo para el primer nivel del árbol tenemos:
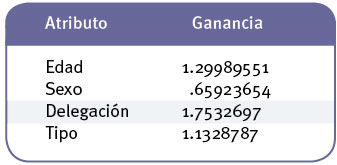
Esto nos da el primer nodo de nuestro árbol, el nodo seleccionado es aquel que presenta la mayor ganancia. El proceso continúa hasta explorar nuevamente los atributos restantes y obtener los nodos del árbol de los niveles inferiores.
En el mercado existen varias herramientas comerciales que realizan el minado de datos. Éstas desarrollan técnicas de aprendizaje automatizado y permiten aplicarlas a problemas reales de minería de datos. También se encuentran disponibles en el web algunas herramientas como Weka y See5, ambas contienen diversos algoritmos de clasificación y asociación.
La siguiente figura presenta una fracción del árbol de decisión, obtenido de efectuar la minería en el conjunto de datos seleccionados.
En el árbol podemos observar que la delegación es el principal atributo que interviene en la selección de una marca particular de vehículo, en el caso de las delegaciones, en particular los casos de Azcapotzalco y Gustavo A. Madero, se observa que el siguiente factor determinante es la edad de la persona, sin embargo, en Naulcalpan se observa que se tienen motivos particulares que marcan la preferencia en la selección del auto, por ejemplo: la gente prefiere Toyota si se guían por los costos y calidad de los servicios. Por supuesto mientras más grande y variado sea el conjunto de datos seleccionados, el resultado será más aproximado a la realidad.
La minería de datos en este ejemplo nos permitió obtener conclusiones que, a simple vista no son aparentes: uno no esperaría que la delegación fuera un factor determinante en la selección de un vehículo, esperando que cuestiones como el precio o los servicios fueran más significativos. Sin embargo, el proceso de minado descubre esta relación. El analista de datos debe ahora interpretarla. Por ejemplo, es posible que la variable delegación esté actuando como un indicador del estilo de vida de las personas, lo que definitivamente influiría en la elección del auto a comprar. Esta interpretación parece apoyada por el hecho de que las personas más jóvenes prefieran autos de línea más deportiva.

Minería de datos en la empresa
Las técnicas de minería de datos, pueden ser implementadas en las empresas para el descubrimiento de información, aportando valor a los procesos de negocio, por ejemplo, incrementando niveles de venta, aumentando la diversificación de mercado, y mejorando la satisfacción del cliente, entre otros. En general, el proceso de toma de decisiones mejora de manera significativa.
Las aportaciones que este tipo de tecnología puede hacer en las empresas, son encausadas a mantener el nivel competitivo de la empresa, los beneficios de la minería como la capacidad de identificar patrones, comportamientos, reglas y relaciones en los datos, permiten realizar previsiones y encontrar nuevas soluciones o rutas de acción.
Para obtener el valor máximo de las técnicas de minería en las soluciones de inteligencia de negocio, es necesario contar con tecnología que pueda llevar a cabo el proceso en tiempos satisfactorios al negocio y pueda permitir a los tomadores de decisiones, en cada nivel de su organización, analizar la información y actuar con base a los resultados obtenidos.
Referencias
[ Sholom Weiss, Nitin Indurkhya,Tong
Zhang & Fred J. Damerau. Text Mining.
Springer, 2005 ]
[ Ian H. Witten, Eibe Frank. Data Mining:
Practical Machine Learning Tools and
Techniques. Second Edition ]
Acerca del Autor
Dafne Rosso ha participado desde 1998 en iniciativas orientadas a la implementación de soluciones basadas en inteligencia de negocio. Actualmente cursa el Doctorado en Ciencias Computacionales en el área de Sistemas Inteligentes, que se imparte en ITESM. Cuenta con una maestría en Ciencias Computacionales del ITESM y una maestría en Tecnologías de Información y Administración del ITAM, así como numerosos cursos de especialización en tecnología de punta.
Actualmente y desde hace un par de décadas, la cantidad de información que se genera en los medios comerciales, educativos y en general en cualquier sector, se ha incrementado notoriamente. Lo que ha provocado el desarrollo de varias tecnologías enfocadas a aprovechar los datos que se encuentran escondidos en estos grandes volúmenes de información. Algunas de estas tecnologías son por ejemplo los OLAP, Data Warehouse y la Inteligencia de Negocio (Fig. 1), éstas han aportado una considerable mejora en el tratamiento de los datos estructurados y en la mejora de la toma de decisiones. Las bases de datos relacionales (BDR), Data Warehouse (DW), Data Mart (DM), OLAP y OLTP son tecnologías que permiten obtener conclusiones en base a consultas predeterminadas, es decir, son consultas deductivas, realizadas de manera óptima en tiempos cortos y enormes volúmenes de información, conclusiones que serían imposibles de obtener en un proceso manual.Minería de datos
Minería de datos es un concepto que involucra la obtención de conocimiento en forma práctica, no en el sentido teórico. El punto de interés principal, es el de descubrir y describir patrones encontrados en los datos. Pretende resolver problemas o pronosticar nuevos datos a partir de los datos ya presentes que se encuentren en el Data Warehouse corporativo. Por ejemplo: permiten pronosticar la lealtad de un cliente en función de los patrones encontrados en su comportamiento, otro tipo de aplicaciones se encuentran en la predicción de fraudes, fallas de maquinarias, y múltiples aplicaciones orientadas al servicio.
Fig. 1 Tecnologías para el tratamiento de información.
Fig. 2 Aportación de las tecnologías en el tratamiento de información.
Las técnicas de minería de datos al día de hoy se encuentran plenamente desarrolladas, y para algunos tipos de análisis se encuentran en fase de maduración. Los métodos de minería de datos operan sobre datos altamente estructurados (Fig. 3), que se encuentran en repositorios como Data Warehouse o Data Marts, o bien son resultado de aplicar en ellos algún análisis OLAP. Para efectuar la minería es necesario que se realice previamente una preparación sobre los datos, que les provea de la estructura necesaria para la técnica de minería a emplear.
Figura 3. Minería de datos
El proceso de descubrimiento de patrones puede ser automático o semiautomático, los patrones identificados deben ser significativos y aportar alguna ventaja, usualmente de tipo económico.
Aplicación de la minería de datos
Las técnicas empleadas en la minería de datos dependen del tipo de conocimiento que se desee obtener. Existen dos clasificaciones que agrupan los algoritmos de minería, estas son: minería dirigida y no dirigida. Para el primer caso se conoce el tipo de decisión (clase) al que se desea llegar, como por ejemplo: booleano (si /no), tipo, acción.
Las entradas son de tipo numérico o bien de tipo nominal. Los datos numéricos presentan valores talesvv que las comparaciones en rangos tengan sentido, mientras que los datos nominales tienen un significado específico. El dato nominal más común es algo que puede ser clasificado como cierto o falso.
A continuación vamos a realizar un ejemplo de minería dirigida con una muestra de datos referentes a las preferencias de compra de automóviles. La muestra fue recabada dentro de una población reducida de clase media, cuyo centro de trabajo se encuentra en la zona centro de la ciudad. Los tipos de datos son nominales.
La siguiente figura presenta un extracto del conjunto de datos nominales, previamente procesados para realizar la minería.
Figura 6. Preferencias en compra de automóviles.
Tabla 1. Cálculo de entropía primer nivel.
El dato que se pretende pronosticar es la marca. Es decir, si se presenta un nuevo individuo a comprar un vehículo, ¿cuál es la marca que podría escoger?
Realicemos la minería paso a paso, con un pequeño subconjunto de los datos anteriores, el método que emplearemos se conoce como ID3, éste es una estrategia que divide y conquista, que opera tratando de maximizar el nivel de ganancia en cada paso. La siguiente tabla contiene el cálculo de la entropía para el atributo edad, se realiza el cálculo de la entropía de cada atributo, la cuál es una medida de la incertidumbre existente en el conjunto de atributos, de los cuales se escoge sólo aquel atributo con mayor ganancia (diferencia entre la entropía del sistema y la entropía del atributo). El atributo seleccionado es el nodo del árbol. Este cálculo se repite desde la selección de la raíz y para cada nivel del árbol.
Calculando las entropías de cada atributo para el primer nivel del árbol tenemos:
Esto nos da el primer nodo de nuestro árbol, el nodo seleccionado es aquel que presenta la mayor ganancia. El proceso continúa hasta explorar nuevamente los atributos restantes y obtener los nodos del árbol de los niveles inferiores.
En el mercado existen varias herramientas comerciales que realizan el minado de datos. Éstas desarrollan técnicas de aprendizaje automatizado y permiten aplicarlas a problemas reales de minería de datos. También se encuentran disponibles en el web algunas herramientas como Weka y See5, ambas contienen diversos algoritmos de clasificación y asociación.
La siguiente figura presenta una fracción del árbol de decisión, obtenido de efectuar la minería en el conjunto de datos seleccionados.
En el árbol podemos observar que la delegación es el principal atributo que interviene en la selección de una marca particular de vehículo, en el caso de las delegaciones, en particular los casos de Azcapotzalco y Gustavo A. Madero, se observa que el siguiente factor determinante es la edad de la persona, sin embargo, en Naulcalpan se observa que se tienen motivos particulares que marcan la preferencia en la selección del auto, por ejemplo: la gente prefiere Toyota si se guían por los costos y calidad de los servicios. Por supuesto mientras más grande y variado sea el conjunto de datos seleccionados, el resultado será más aproximado a la realidad.
La minería de datos en este ejemplo nos permitió obtener conclusiones que, a simple vista no son aparentes: uno no esperaría que la delegación fuera un factor determinante en la selección de un vehículo, esperando que cuestiones como el precio o los servicios fueran más significativos. Sin embargo, el proceso de minado descubre esta relación. El analista de datos debe ahora interpretarla. Por ejemplo, es posible que la variable delegación esté actuando como un indicador del estilo de vida de las personas, lo que definitivamente influiría en la elección del auto a comprar. Esta interpretación parece apoyada por el hecho de que las personas más jóvenes prefieran autos de línea más deportiva.
Minería de datos en la empresa
Las técnicas de minería de datos, pueden ser implementadas en las empresas para el descubrimiento de información, aportando valor a los procesos de negocio, por ejemplo, incrementando niveles de venta, aumentando la diversificación de mercado, y mejorando la satisfacción del cliente, entre otros. En general, el proceso de toma de decisiones mejora de manera significativa.
Las aportaciones que este tipo de tecnología puede hacer en las empresas, son encausadas a mantener el nivel competitivo de la empresa, los beneficios de la minería como la capacidad de identificar patrones, comportamientos, reglas y relaciones en los datos, permiten realizar previsiones y encontrar nuevas soluciones o rutas de acción.
Para obtener el valor máximo de las técnicas de minería en las soluciones de inteligencia de negocio, es necesario contar con tecnología que pueda llevar a cabo el proceso en tiempos satisfactorios al negocio y pueda permitir a los tomadores de decisiones, en cada nivel de su organización, analizar la información y actuar con base a los resultados obtenidos.
Referencias
[ Sholom Weiss, Nitin Indurkhya,Tong
Zhang & Fred J. Damerau. Text Mining.
Springer, 2005 ]
[ Ian H. Witten, Eibe Frank. Data Mining:
Practical Machine Learning Tools and
Techniques. Second Edition ]
Acerca del Autor
Dafne Rosso ha participado desde 1998 en iniciativas orientadas a la implementación de soluciones basadas en inteligencia de negocio. Actualmente cursa el Doctorado en Ciencias Computacionales en el área de Sistemas Inteligentes, que se imparte en ITESM. Cuenta con una maestría en Ciencias Computacionales del ITESM y una maestría en Tecnologías de Información y Administración del ITAM, así como numerosos cursos de especialización en tecnología de punta.
- Log in to post comments