Publicado en
Al realizar pruebas de desempeño (performance), debemos entregar resultados lo antes posible, de manera que minimicemos el costo de estas y permitir que se implementen las mejoras lo antes posible. En este artículo se presenta una estrategia para realizar las pruebas de performance de una manera ágil, a través de llevar a cabo ciertas acciones de manera temprana dentro del ciclo de desarrollo de un aplicación dada y con la colaboración del equipo de desarrollo.
El enfoque tradicional
Existen distintos tipos de pruebas de desempeño: load test (test de carga), donde la idea es simular la realidad a la que estará expuesto el sistema cuando esté en producción; stress test, donde se va más allá de la carga esperada para ver dónde se “truena” el sistema; endurance (resistencia), para ver cómo se desempeña el sistema luego de una carga duradera por un período largo de tiempo, etcétera.
Cualquiera que sea el tipo de prueba de rendimiento a realizar, requiera una preparación que lleva un esfuerzo no despreciable.
- Es necesario hacer un análisis y diseño de la carga que se quiere simular. Esto incluye: duración de la simulación, casos de prueba, cantidades de usuarios que los ejecutarán, cuántas veces por hora, ramp-up (velocidad y cadencia con la que ingresan usuarios virtuales al inicio de una prueba), etcétera.
- Luego de diseñado el “escenario de carga” pasamos a preparar la simulación con la(s) herramienta(s) de simulación de carga. A esta tarea se le denomina automatización o robotización y es en cierta forma una tarea de programación. Por más que estemos utilizando herramientas de última generación, esto involucra tiempo que separa más el día de inicio del proyecto del día en que se comienzan a reportar datos sobre el desempeño del sistema a nuestro cliente.
- Por último, comenzamos con la ejecución de las pruebas. Esto lo hacemos con toda la simulación preparada y las herramientas de monitoreo configuradas para obtener los datos de desempeño de los distintos elementos que conforman la infraestructura del sistema bajo pruebas. Esta etapa es un ciclo de ejecución, análisis y ajuste, que tiene como finalidad lograr mejoras en el sistema con los datos que se obtienen luego de cada ejecución.
A medida que se adquiere experiencia con las herramientas, los tiempos de automatización van mejorando. Pero aun así, ésta sigue siendo una de las partes más pesadas de cada proyecto. Generalmente se intenta acotar la cantidad de casos de prueba que se incluyen en un escenario de carga para mantenerse en un margen aceptable, intentando no incluir más de 15 casos de prueba (varía dependiendo del proyecto, la complejidad del sistema y los recursos y tiempo disponibles).
El enfoque tradicional de pruebas de desempeño plantea un proceso en cascada, en donde no se comienza a ejecutar pruebas hasta que se hayan superado las etapas previas de diseño e implementación de las pruebas automatizadas. Una vez que esto está listo el proceso de ejecución inicia, y a partir de ese momento el cliente comienza a recibir resultados (ver figura 1). Es decir que desde que el cliente firmó el contrato hasta que recibe un primer resultado pueden pasar un par de semanas. Aunque parezca poco, esto es demasiado para las dimensiones de un proyecto de performance, que generalmente no dura más de uno o dos meses.
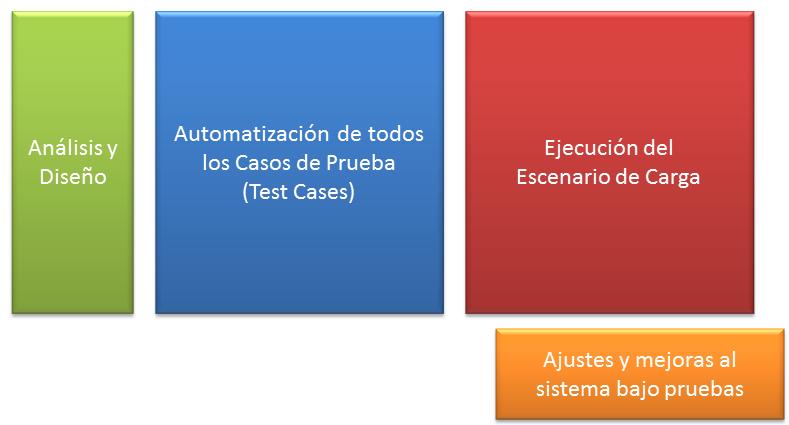
Figura 1. El enfoque tradicional de pruebas de desempeño
Es necesario agilizar este proceso tradicional para brindar resultados lo antes posible. Así el equipo de desarrollo podrá realizar mejoras cuanto antes, y estaremos verificando prontamente la validez de nuestras pruebas. Si tenemos algún error en el análisis o diseño de las pruebas y nos enteramos de esto hasta el final, eso será muy costoso de corregir; de la misma forma que un bug es más costoso para un equipo de desarrollo cuando se detecta en producción.
Agilizando el proceso
Veamos entonces algunas ideas de cómo agilizar este proceso.
Entregar resultados desde que estamos automatizando.
Aunque el foco de la automatización no es encontrar errores o mejoras al sistema, si estamos atentos podemos detectar posibilidades de mejora. Esto es posible dado que la automatización implica trabajar a nivel de protocolo, y se termina conociendo y analizando bastante el tráfico de comunicación entre el cliente y el servidor.
Por ejemplo, en el caso de un sistema Web, es posible encontrar posibilidades de mejora tales como:
- Manejo de cookies.
- Problemas con variables enviadas en parámetros.
- Problemas de seguridad.
- HTML innecesario.
- Recursos inexistentes (imágenes, css, js, etc.).
- Redirecciones innecesarias.
Es cierto que el equipo de desarrollo debería detectar estos errores previamente; sin embargo la realidad muestra que en la mayoría de los proyectos se encuentran muchos de estos incidentes. Por eso, al realizar estas pruebas estamos entregando resultados de valor que mejorarán el rendimiento del sistema.
Pipeline entre automatización y ejecución.
Para poder comenzar a automatizar pruebas para usarlas en pruebas de desempeño no es necesario esperar a contar con todo el conjunto de pruebas armado. En cuanto tengamos los primeros casos de prueba podemos comenzar a automatizarlos y aplicarlos (ver figura 2).
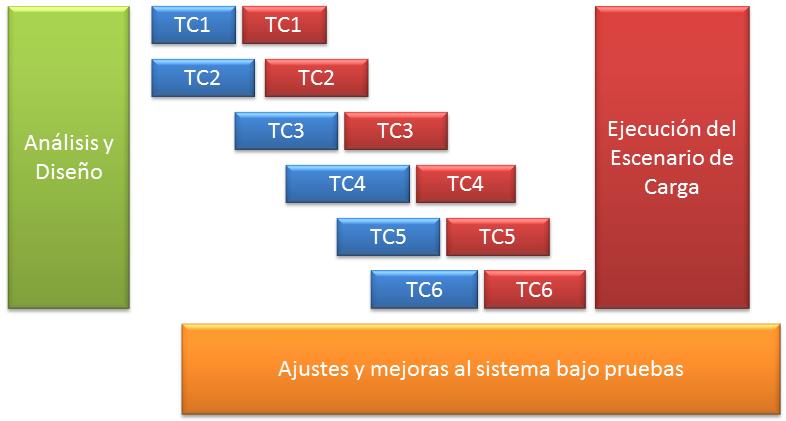
Figura 2. Flujo ágil de pruebas de desempeño
Este pipeline nos da mayor agilidad para obtener resultados lo antes posible en la automatización de pruebas, aprovechando ejecutar pruebas iniciales con cada nuevo caso de prueba que se automatice. También nos permite analizar cómo se comporta cada caso de prueba en específico. Estas pruebas son de gran valor porque permiten encontrar problemas de concurrencia, bloqueos de acceso a tablas, falta de índices, utilización de caché, tráfico, etcétera.
Para cuando completemos la automatización de todos los casos de prueba, el equipo de desarrollo ya estará trabajado en las primeras mejoras que les fuimos reportando, habiendo así solucionado los primeros problemas que hubiesen aparecido al ejecutar pruebas. Otra ventaja es que las pruebas con un solo caso de prueba son más fáciles de ejecutar que las pruebas con 15 casos de prueba, pues es más fácil preparar los datos, analizar los resultados, e incluso analizar cómo mejorar el sistema.
Otra técnica que se utiliza es ejecutar una prueba en la que haya sólo un usuario ejecutando un caso de prueba, pues de esa forma se obtendría el mejor tiempo de respuesta que se puede llegar a tener para ese caso de prueba, pues toda la infraestructura está dedicada en exclusiva para ese usuario. Esta prueba debería ejecutarse al menos con 15 datos distintos a modo de tener datos con cierta validez estadística, y no tener tiempos afectados por la inicialización de estructuras de datos, de cachés, compilación de servlets, etcétera, que nos hagan llegar a conclusiones equivocadas. Con esto podemos ver cuál es el tiempo de respuesta que tiene el caso de prueba funcionando “solo”, para luego comparar estos tiempos con los de la prueba en concurrencia con otros casos y ver cómo impactan unos sobre otros. Lo que suele pasar es que algunos casos de prueba bloqueen tablas que otros utilizan y de esa forma repercutan en los tiempos de respuesta al estar en concurrencia. Esta comparación no la podríamos hacer tan fácil si ejecutamos directamente la carga completa.
Considerar el rendimiento desde el desarrollo.
Generalmente los desarrolladores no consideran el rendimiento desde el comienzo de un proyecto. Con un poco de esfuerzo extra se podrían solucionar problemas en forma temprana, y hablamos de problemas graves: arquitectura, mecanismos de conexión, estructuras de datos, algoritmos. Como equipo de testing, siempre felicitamos a los desarrolladores que hacen una prueba en la cual simplemente instancian varios procesos (digamos unos 30, por poner un número, pero dependerá de cada sistema y de la infraestructura disponible para ejecutar la prueba), en el cual se ejecuta la funcionalidad que nos interesa con cierta variedad de datos. Esta práctica nos puede anticipar una enorme cantidad de problemas, que serán mucho más difíciles de resolver si los dejamos para una última instancia. Si sabemos que vamos a ejecutar pruebas de performance al final del desarrollo, tenemos una tranquilidad muy grande. Pero tampoco es bueno confiarse en eso y esperar hasta ese momento para trabajar en el rendimiento del sistema. Podremos mejorar el desempeño de todo el equipo y ahorrar costos del proyecto si tenemos en cuenta estos aspectos en forma temprana, desde el desarrollo.
Conclusión
Sin duda las pruebas de performance son muy importantes y nos dan una tranquilidad muy grande a la hora de poner un sistema en producción. El problema es seguir un proceso en cascada para ponerlo en práctica: es necesario agilizar las pruebas de performance. Mientras más temprano obtengamos resultados, más eficientes seremos en nuestro objetivo de garantizar el rendimiento (performance) de un sistema.
Federico Toledo (@fltoledo) es ingeniero en Computación por la Universidad de la República de Uruguay y sustenta la maestría de Informática por la universidad de Castilla-La Mancha en España. Actualmente se encuentra realizando sus estudios de doctorado enfocados a la especialización en el diseño de pruebas automáticas para sistemas de información y es socio co-fundador de Abstracta (www.abstractaconsulting.com), empresa con presencia en México y Uruguay, que se dedica a servicios y desarrollo de productos para testing.
- Log in to post comments