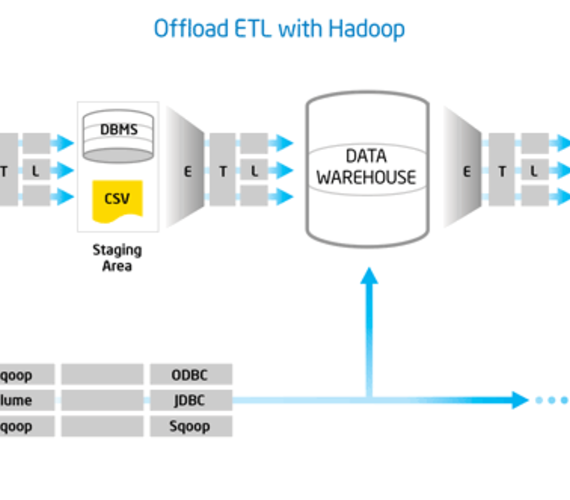
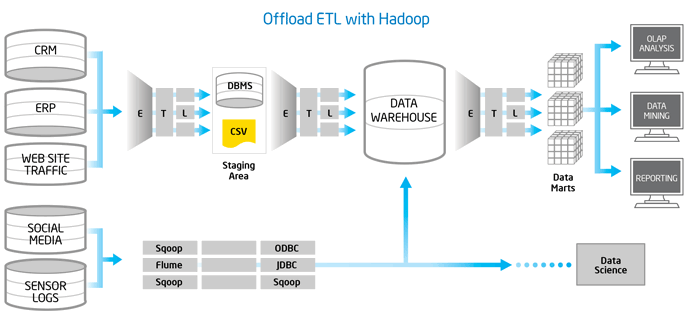
El reto de extraer valor del big data es similar en muchas formas al ya conocido problema de destilar inteligencia de negocio a partir de datos transaccionales. En el corazón de este reto está el proceso utilizado para extraer datos a partir de múltiples fuentes, transformarlos de acuerdo a las necesidades de análisis y cargarlos a un data warehouse, esto es lo que se conoce como ETL (Extract -> Transform -> Load).
Por su parte, Apache Hadoop se ha establecido como el estándar de facto para gestionar big data. Hadoop está diseñado para operar de forma elástica, aprovechando de forma eficiente la infraestructura de cómputo. Así que es de gran interés considerar la utilización Hadoop para realizar el proceso de ETL.
En este whitepaper preparado por Intel, se examinan algunas consideraciones y recomendaciones al utilizar Hadoop para ETL.
- Log in to post comments