Según Aberdeen Group, 90% de los proyectos de software se liberan tarde, mientras que Gartner comenta que 50% de los proyectos de software excede su presupuesto inicial. Existen muchas razones para esto, pero una de las más comunes es que no se realiza una estimación adecuada.
La información que se espera obtener a través de la estimación en un proyecto de software es la siguiente:
• Tamaño del producto
• Esfuerzo requerido
• Duración del proyecto
• Recursos necesarios
• Calidad esperada
Como ya mencionamos, las malas estimaciones —o las no estimaciones— son una de las principales causas de fracaso en los proyectos. Esto típicamente sucede por no contar con un proceso estructurado para la estimación, lo cual hace casi imposible definir equipos de trabajo de magnitud adecuada y plazos de cumplimiento razonables. La situación empeora cuando no se cuenta con información de proyectos anteriores. Todo esto hace que la estimación sea uno de los temas que más preocupa a los administradores de proyectos de software.
Un problema inherente a la estimación es que conforme aumenta el tamaño del proyecto, disminuye la precisión de los resultados obtenidos (ver gráfica 1).
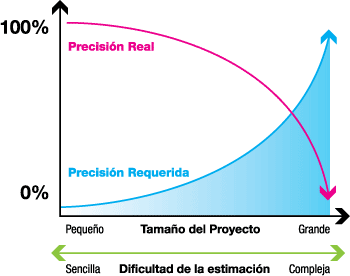
Entonces, ¿qué debemos hacer para que nuestra estimación sea precisa, exitosa y cumpla los objetivos que buscamos? Comencemos por entender las dos características principales de cualquier estimación: que sea explicable y que sea revisable.
• Explicable.- Es común que al preguntar a las personas cómo llegaron al resultado de una estimación, ellas mismas no lo puedan explicar. Una buena estimación debe de tener suficiente claridad y modularidad para que sea entendible y cualquier persona pueda comprender los valores de todos sus componentes.
• Revisable.- A medida que el proyecto va avanzando, la cantidad de información que se tiene va siendo cada día mayor, y la misma nos ayuda a ir corrigiendo la estimación. Es importante definir límites superiores e inferiores para la estimación, dependiendo de la etapa en la que se encuentre (ver gráfica 2).
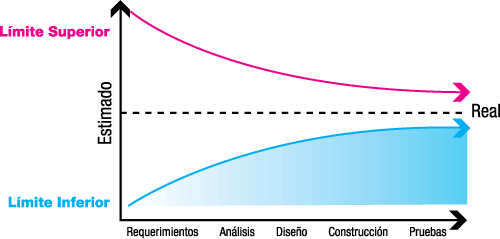
Gracias a estos límites, y con la ayuda de cierta información histórica, podremos ir revisando nuestro proyecto para saber si seguimos dentro del estimado. Tomemos como ejemplo un proyecto de 500 horas hombre. Nuestra información histórica nos indica que el levantamiento de requerimientos lleva cerca de 20% del tiempo, el diseño 30%, el desarrollo 25%, y las pruebas, junto con la puesta en producción, 25% restante. Imaginemos que habíamos planeado el levantamiento de requerimientos en 100 horas, pero en realidad se lleva 120. En este momento es cuando se tiene que revisar el estimado, ya que sería incorrecto asumir que solamente vamos con 20 horas de retraso, cuando en realidad llevamos un retraso de 20%. En este caso, tendríamos que revisar el proyecto y agregar 20% al esfuerzo en todas las fases. Nuestro nuevo estimado sería de 600 horas.
La duración definida para un proyecto rara vez surge como resultado de una estimación, sino que es negociada entre el cliente (ya sea interno o externo) y el equipo de desarrollo. Suele suceder que se busque acortar el tiempo en función de aumentar el número de recursos, pero sabemos que esta relación no es del todo correcta. De aquí la existencia de frases como “no porque una persona pinte una casa en diez días debemos concluir que diez personas lo harán en un día”. Otro error común es no tomar en cuenta las limitaciones de recursos disponibles. Debemos aprender a estimar en base a los recursos que se tienen, no a los que quisiéramos tener.
Sentando estos antecedentes, expliquemos dos métodos comunes para estimar de proyectos de software.
COCOMO
Desarrollado en la Universidad del Sur de California con Barry Boehm como principal autor. Su nombre significa “Constructive Cost Model” (modelo constructivo de costo). El modelo original data de 1981, pero en el 2000 se liberó COCOMO II, una versión ajustada para el tipo de proyectos realizados actualmente. Este modelo se basa en la siguiente información para realizar una estimación:
• Tamaño del sistema.- Normalmente medido en KSLOCs o miles de líneas de código —la K representa un millar, y SLOC es el acrónimo de “source lines of code”—. Esta información se puede obtener en base a sistemas existentes, aunque también existen métodos para estimar el tamaño de un sistema en base a su funcionalidad (ver puntos de función más adelante).
• Factores de escala.- Contabilizan las economías o deseconomías de escala en el proyecto. Cuando un proyecto exhibe economías de escala, significa que si el tamaño del producto se duplica, el esfuerzo necesario es menos del doble, mientras que cuando hay deseconomías de escala, el esfuerzo requerido aumenta a un ritmo mayor que el tamaño del producto. Entre los factores que mejoran las economías de escala están la cohesión del equipo y la madurez de procesos en la organización. Sin embargo, en general los proyectos de software exhiben deseconomías de escala.
• Multiplicadores de esfuerzo.- Características del proyecto que afectan el esfuerzo requerido para desarrollarlo. Algunos ejemplos son el nivel del personal disponible, las herramientas utilizadas o la complejidad del lenguaje.
La fórmula para estimar esfuerzo es del tipo:
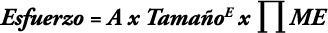
Donde A es una constante, E es un indicador de economías de escala (calculado en base a los factores de escala), y ME es el promedio de valores de los multiplicadores de esfuerzo.
La fórmula para estimar la duración es del tipo:
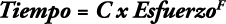
Donde C es una constante y F es un valor derivado de los factores de escala.
Existen valores por defecto para las constantes, pero lo ideal es calibrarlas en base a la información histórica de proyectos en la organización.
En general, COCOMO es una buena opción para realizar estimaciones “macro”, con el objetivo de asignar presupuesto a un proyecto, o decidir si vale la pena desarrollar/reemplazar un sistema.
Puntos de Función
Otra alternativa para dimensionar un sistema es utilizando “function points” (FPs) o puntos de función. Este método fue creado por Allan Albrecht, y es una manera de cuantificar la capacidad funcional de un sistema de software. Los pasos para determinar los puntos de función en un sistema son:
- 1. Identificar los elementos generadores de funcionalidad. Estos pueden ser de cinco tipos: transacciones de entrada, transacciones de salida, transacciones de búsqueda, archivos lógicos internos y archivos de interfase externa.
2. Calificar cada elemento y asignarle un valor. Cada elemento se califica como “simple”, “promedio” o “complejo”, dependiendo de la cantidad de datos que maneje; posteriormente, asignar una cantidad de puntos a cada elemento. Por ejemplo, una búsqueda de complejidad baja corresponde a 4 puntos, mientras que una salida de complejidad alta corresponde a 7. Existen tablas con los valores correspondientes a cada caso (ver las referencias).
3. Sumar los puntos asignados a cada elemento para generar un total conocido como “puntos de función sin ajustar” (UFP por sus siglas en inglés).
4. Determinar el factor de complejidad técnica (TCF). Identificar las características técnicas relevantes al proyecto, tales como requerimientos de desempeño, confiabilidad e interacción con otros sistemas. Con esto se calcula un factor de ajuste cuyo valor va de .65 a 1.35.
5. Estimar los puntos de función ajustados. FP = UFP * TCF
Con esto ya podemos determinar el tamaño de un sistema. Pero ahora, ¿cómo podemos obtener el esfuerzo y duración del proyecto? Imaginemos que vamos a desarrollar un sistema de 100 FPs, y que usaremos un ciclo de vida tradicional en cascada con las siguientes etapas: análisis de requerimientos, diseño, construcción, pruebas y liberación a producción.
Basándonos en registros históricos, podemos determinar la relación que hay entre la cantidad de FPs de un sistema y el esfuerzo requerido para cada etapa. Por ejemplo, podríamos concluir que el análisis requiere 2 horas-hombre por cada FP, y como nuestro sistema tiene 100 FPs entonces podemos esperar que el análisis se lleve 200 horas-hombre. La tabla 1 muestra el ejemplo completo.
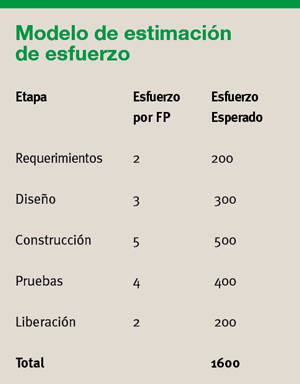
Este ejemplo sólo llega al nivel de detalle de etapas. Un modelo real debe contemplar todas las actividades a realizar dentro del proyecto, incluyendo juntas de revisión y otras tareas que rara vez se toman en cuenta en una estimación. La idea de este método es que sirva de base para la planeación de actividades y asignación de recursos en un plan de trabajo detallado.
Conclusión
Hemos delimitado la importancia y dificultades de la estimación de proyectos de software. Mencionamos dos métodos de estimación: uno orientado a generar valores agregados para la toma de decisiones, y otro orientado a generar información detallada para la planeación. En próximos artículos hablaremos más a fondo sobre ellos. Es un hecho que ningún modelo va a dar una alta precisión en un inicio, poco a poco deben irse ajustando en base a la información obtenida cada que se realiza un proyecto.
Referencias:
Gramajo, E. et al. Combinación de Alternativas para la Estimación de Proyectos de Software. CAPIS - Centro de Actualización Permanente en Ingeniería de Software.
Boehm, Barry et al. Software Cost Estimation with COCOMO II. Prentice Hall, 2000.
Longstreet, David. “Fundamentals of Function Point Analysis”. www.ifpug.com/fpafund.htm
Acerca del autor Rodrigo García es Technical Solutions Manager en Softtek Information Services en Monterrey, N.L., donde es responsable de la estimación de propuestas para proyectos de desarrollo. Rodrigo es Ingeniero en Sistemas Computacionales del ITESM y actualmente cursa el MBA en Global e-Management en la misma institución.
- Log in to post comments