El proceso de normalización de bases de datos tiene como objetivo optimizar técnicamente el diseño de las mismas. Así, es posible minimizar redundancias y evitar anomalías relacionadas con la manipulación de los datos.
Existen distintos niveles de normalización, según diferentes autores. Sin embargo, es común encontrar que, en la práctica, llegar a la tercera forma normal es suficiente. La mayoría de la literatura, enfatiza también la cuarta forma normal, la forma normal de Boyce-Codd, y la quinta forma normal. Cada paso de una forma a la siguiente implica fragmentar la base de datos en más tablas, por lo que es común que nos preguntemos hasta dónde debemos llegar, y si realmente es mejor normalizar al máximo la base de datos para obtener un diseño óptimo.
Empecemos por entender la normalización básica, con el fin de obtener mayor claridad en la respuesta.
Supongamos que tenemos la siguiente tabla de empleados:

Figura 1. Tabla inicial
Para entender el estado de esta tabla, es importante conocer las relaciones entre sus atributos. El número de nómina nos permite determinar los valores de todas las columnas en un registro, por lo que está subrayada, indicando que se trata de la llave primaria.
Para encontrarse en primera forma normal, es necesario no tener grupos repetidos. Esto significa que ninguna celda en la tabla debe contener más de un valor. Este no es el caso, ya que Luisa López tiene dos números telefónicos. Con el fin de tener celdas atómicas, tendríamos que crear un nuevo registro para Luisa y dividir sus números telefónicos de modo que quedara uno en cada renglón. Esto tendría como consecuencia que el número de nómina se repetiría y ya no serviría como identificador único, por lo que es necesario crear una llave compuesta entre el número de nómina y el atributo con más de un valor, es decir, el número telefónico. De esta manera, la nueva tabla en primera forma normal quedaría como se indica a continuación:

Figura 2. Estructura en primera forma normal
Nótese que el atributo teléfono está ahora también subrayado, indicando que es parte de una llave primaria compuesta.
Para pasar a segunda forma normal, es necesario verificar que no existan dependencias parciales. Es decir, que no existan atributos que puedan ser determinados por una sola parte de la llave primaria compuesta. En realidad, este no es el caso en nuestra tabla, ya que prácticamente todos los atributos se determinan sólo con el número de nómina. Para obtener la segunda forma normal, entonces, es necesario dividir la tabla en dos, dejando los atributos que requieren ambas partes de la llave en una y los que requieren una parte en la otra. De ese modo, nuestras nuevas tablas quedarían así:
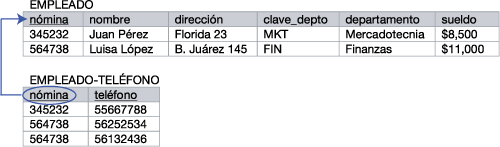
Figura 3. Estructura en segunda forma normal
Noten ahora que el atributo nómina en la segunda tabla, está ahora circulada, indicando que se ha convertido en una llave foránea, que apunta a la primera tabla. Una llave foránea se define como un atributo en una tabla, que es también la llave primaria de otra. Es una redundancia necesaria para poder conectar las tablas entre sí. Sin embargo, este paso eliminó la redundancia causada por la repetición del registro de Luisa López que teníamos en la primera forma normal. Finalmente, para llegar a tercera forma normal, es necesario eliminar las dependencias transitivas. Estas existen, cuando la llave primaria determina el valor de un atributo a través de otro. En nuestra tabla de empleado, podemos conocer el nombre del departamento a través de la clave del mismo. Por ello, es necesario crear una nueva tabla para departamento, quedando nuestro esquema como se muestra a continuación:

Figura 4. Estructura en tercera forma normal
Ahora nuestro esquema se encuentra en tercera forma normal, lo cual es lo que más frecuentemente encontramos en la práctica. Sin embargo, ¿es esto siempre lo más deseable?
Nuestro ejemplo es muy sencillo, pero muestra como una tabla se terminó convirtiendo en tres. Si pensamos en una base de datos de una aplicación relativamente compleja, esta fragmentación puede convertirse en algo bastante considerable, con cientos de tablas en la base de datos. Esto trae como consecuencia que el desempeño de las consultas se vea seriamente afectado, al tener que hacer sentencias SQL más complicadas, con múltiples joins, afectando seriamente el tiempo de respuesta de la aplicación. A veces, es preferible tener mayor redundancia con tal de poder mejorar el tiempo de respuesta. En esos casos, es preferible desnormalizar a una forma normal anterior. Esto es particularmente importante cuando la redundancia que se está optimizando al normalizar es mínima. La respuesta entonces estará en función de hacer un balance entre la redundancia y el tiempo de respuesta.
Por otro lado, es importante recordar que la normalización sólo es indicada cuando se trata de bases de datos transaccionales. Las bases multidimensionales, normalmente asociadas con la toma de decisiones, como es el caso de las data warehouses y otras aplicaciones OLAP para inteligencia de negocios, no tienen la intención de optimizar su diseño técnicamente, ya que no son bases de producción con grandes operaciones simultáneas, sino que su diseño obedece al proceso mismo de toma de decisiones. Así, las tablas se clasifican en tablas de hechos y de dimensiones. Las tablas de hechos contienen aspectos cuantitativos de análisis, como ventas en moneda y en unidades, margen de ganancia, etc. Las dimensiones representan los diferentes agrupamientos o perspectivas desde los cuales se desea analizar la información cuantitativa contenida en las tablas de hechos. Así, algunos ejemplos de tablas de dimensiones incluirían regiones, períodos de tiempo, líneas de productos, etc.
Las bases orientadas a la toma de decisiones llevan una redundancia intencional, ya que es necesario almacenar los datos de un objeto de interés (como por ejemplo los clientes) en una sola tabla. La idea es tener datos con diferentes niveles de agregación y de manera histórica en la base, para su consulta rápida y efectiva por parte del tomador de decisiones.
En algunas ocasiones, se implantan cubos de análisis y visualización sobre bases de datos transaccionales, con el fin de facilitar decisiones a niveles más operativos. En esos casos, se pueden establecer réplicas de las mismas, para no afectar la eficiencia y desempeño de la operación, y desnormalizar para obtener niveles de redundancia que permitan un análisis más efectivo.
Y la respuesta es ...
Como normalmente ocurre, la respuesta a nuestra pregunta de cuándo y hasta dónde normalizar dependerá del objetivo de la base de datos, así como de la naturaleza de los datos mismos. Lo importante es desarrollar la habilidad para aplicar criterios de optimización en cada contexto.
Acerca del autor
El Dr. Guillermo Rodríguez Abitia es Director de Sistemas de Información en el Tecnológico de Monterrey, Campus Estado de México, donde se especializa en temas como Sistemas Estratégicos, Administración del Conocimiento y Transferencia de Tecnología. Guillermo participa de manera continua en conferencias internacionales, y en 1999 recibió el reconocimiento a la mejor conferencia en el Americas Conference on Information Systems. Es presidente fundador de la Asociación de Sistemas de Información de América Latina y el Caribe.
- Log in to post comments