Published 17 years ago
(updated 14 years ago)
Ejemplo de Ordenamiento de Burbuja Paralelo
Al igual que la mayoría de los ingenieros de sistemas, tengo malos recuerdos de lidiar con threads en mi clase de sistemas operativos en la universidad. Así que cuando me encontré en la necesidad, ya como profesional, de aprender a hacer programas que se ejecuten en distintos threads paralelos, debo aceptar que tuve mucho miedo. Sin embargo, descubrí que actualmente hay herramientas que hacen esto mucho más sencillo de lo que pensaba.
Para reiniciarme en la programación paralela, decidí comenzar haciendo el ejercicio de implementar un ordenamiento de burbuja (bubble sort) paralelo. Éste es uno de los algoritmos de ordenamiento más sencillos y lentos. La forma en que funciona es que se recorre una lista de elementos, y se va comparando el elemento i con el i+1, y en caso de que el orden esté equivocado, se intercambia estos valores de posición. Este recorrido se repite n-1 veces (donde n es el número de elementos que contiene la lista) para asegurar que se hayan realizado los cambios necesarios y la lista está ordenada.
Decidí ordenar palabras, ya que esto me daba una forma sencilla de repartir mis datos entre distintos threads (un thread podría ordenar las palabras que comienzan con “A”, otro las que empiezan con “B”, etc.).
Al iniciar, el programa debe leer un archivo con palabras, contar cuantas palabras comienzan con cada letra (sin diferenciar entre mayúsculas y minúsculas), y guardar esta cuenta en un arreglo unidimensional de 26 elementos llamado letter_counts. Esto significa que el valor de letter_counts[0] es la cantidad de palabras que empiezan con la letra ‘a’, letter_counts[1] es la cantidad de palabras que empiezan con ‘b’, y así sucesivamente. El siguiente paso es volver a leer las palabras del archivo, y almacenarlas en un arreglo de arreglos (my_array), de acuerdo a la letra con la que empiezan. Es decir, my_array[0] apunta a un arreglo que contiene las palabras que comienzan con la letra ‘a’, my_array[1] contiene un arreglo con las palabras que comienzan con la letra ‘b’, y así sucesivamente.
Una vez que se genera este arreglo “semiordenado” –ya que las palabras se encuentran agrupadas de acuerdo a la letra con la que empiezan –, se puede invocar a la función que se encarga del ordenamiento.
Ordenamiento sin paralelismo
Primero realicé la prueba haciendo el ordenamiento de la forma tradicional, es decir sin paralelismo. El listado 1 muestra el código en lenguaje C para hacer esto.
void bubble_sort (char *** &my_array, int letter_counts[26]){
char * temp;
for (int letter =0; letter < 26; letter++) {
for (int i =0; i < letter_counts[letter] - 1 ; i++){
for (int j =0; j < letter_counts[letter] - 1 - i; j++){
if (strcmp(static_cast<char *>(my_array[letter]
[j+1]), static_cast<char *>(my_array[letter][j])) < 0){
temp = my_array[letter][j+1];
my_array[letter][j+1] = my_array[letter][j];
my_array[letter][j] = temp;
}
}
}
}
}
Listado 1. Ordenamiento sin paralelismo
El programa se ejecutó en una máquina con dos procesadores de cuatro núcleos, y al monitorear la ejecución me di cuenta que solo se usaba un núcleo. El tiempo de ejecución del programa fue de 7.4 segundos.
Implementando paralelismo
con OpenMP
Actualmente existen diversas librerías que abstraen y simplifican el manejo de threads. Una de ellas es OpenMP, la cual usé para este ejemplo. OpenMP es un API para programación paralela en C/C++ y Fortran. Es soportado por una gran variedad de compiladores incluyendo el compilador de Intel, gcc, y Visual Studio (2005 o mayor). Con OpenMP, es posible convertir un programa de un modelo single threaded a un modelo multithreaded sin necesidad de escribir un solo fork, join, o siquiera crear un thread de forma explícita. Se implementa en el código por medio de directivas “pragma”. Como programador, lo único que necesitas hacer es determinar qué patrón de paralelismo requiere tu código, y entonces indicar la directiva pragma correspondiente.
Uno de los elementos más sencillos y utilizados de OpenMP es el pragma “parallel for”. Este corresponde a lo que sería un “for” en programación single threaded. Lo que hace es dividir un ciclo de tareas en rangos, y asigna un segmento de tareas a cada procesador. OpenMP se encarga de crear los threads y asignarlos a cada procesador. En el caso de mi ejemplo, el pragma “parallel for” es justo lo que necesitaba, ya que mi algoritmo estaba estructurado en base a un ciclo maestro donde se trabaja de forma separada los distintos grupos de palabras en base a la letra con la que empiezan. Usando el parallel for a este nivel, no corría el riesgo de que dos threads accedieran el arreglo de la misma letra al mismo tiempo .El listado 2 muestra el código correspondiente, agregando el parallel for.
void parallel_bubble_sort (char *** &my_array,
int letter_counts[26]){
char * temp;
#pragma omp parallel for
for (int letter =0; letter < 26; letter++) {
for (int i =0; i < letter_counts[letter] - 1 ; i++){
for (int j =0; j < letter_counts[letter] - 1 - i; j++){
if (strcmp(static_cast<char *>(my_array[letter]
[j+1]), static_cast<char *>(my_array[letter][j])) < 0){
temp = my_array[letter][j+1];
my_array[letter][j+1] = my_array[letter][j];
my_array[letter][j] = temp;
}
}
}
}
}
Listado 2. Ordenamiento usando el parallel for
Eso fue bastante sencillo … ¿podría ser tan bello? Al ejecutar este código y monitorear el sistema me di cuenta que ya había actividad en los distintos núcleos de procesamiento. El tiempo de ejecución fue de 6.4 segundos, lo cual significó una pequeña reducción. Sin embargo, al verificar los resultados encontré que había errores ya que el arreglo no había sido ordenado correctamente. Muy probablemente esto se debía a que generé un error de data race. Un data race es cuando distintos threads acceden y modifican una misma variable de forma no coordinada; típicamente esto genera resultados erróneos en el valor de las variables.
Depurando con Intel Thread
Checker
Para encontrar el error, decidí utilizar el Intel Thread Checker. Este es un depurador para programas multithreaded. Lo que hace es monitorear la ejecución de un programa para encontrar errores como data races, deadlocks, fallas de sincronización, y tiempos de espera. La figura 1 muestra los resultados del Intel Thread Checker.
Los primeros dos errores indicaban que mis sospechas eran correctas. Al revisar las líneas referidas, noté que la línea 96 era la sentencia:
temp = my_array[letter][j+1];
y la línea 98 era:
my_array[letter][j] = temp;
Así que lo que estaba sucediendo es que distintos threads estaban recurriendo al mismo tiempo a la misma variable temp para reordenar los valores de los arreglos; también encontré warnings, indicando que había threads que esperaban más de 3 segundos para obtener acceso a un recurso, esto es bastante tiempo para un programa cuya ejecución total dura 6 segundos. Probablemente esto se debía a la pelea entre los 8 threads para acceder la misma variable temp. Ya que había encontrado el problema, tendría que pensar en la solución adecuada. Una opción era encerrar las líneas 96 a 98 en una sección crítica, o sincronizada, de forma que al mismo tiempo solamente un thread pudiera estar en esta sección, y hasta que terminara todas las operaciones de la sección liberaría el control para otro thread. Otra opción era hacer que la variable temp fuera local para cada thread.
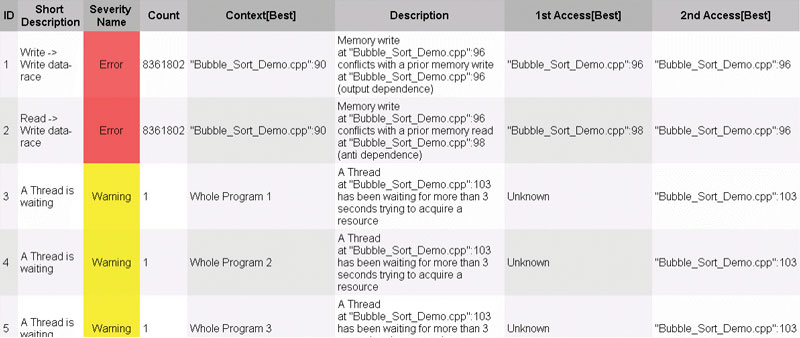
Figura 1. Resultados del Intel Thread Checker
Esta opción me pareció mucho mejor, ya que esta variable no necesitaba ser compartida, y por medio de este mecanismo se evitó que cada thread tuviera que esperar a que los demás terminen.
Afortunadamente, en OpenMP es muy sencillo marcar variables como locales para cada thread. Simplemente se utiliza el comando private. El listado 3 muestra el código resultante.
void parallel_bubble_sort (char *** &my_array,
int letter_counts[26]){
char * temp;
#pragma omp parallel for private(temp)
for (int letter =0; letter < 26; letter++) {
for (int i =0; i < letter_counts[letter] - 1 ; i++){
for (int j =0; j < letter_counts[letter] - 1 - i; j++){
if (strcmp(static_cast<char *>(my_array[letter]
[j+1]), static_cast<char *>(my_array[letter][j])) < 0){
temp = my_array[letter][j+1];
my_array[letter][j+1] = my_array[letter][j];
my_array[letter][j] = temp;
}
}
}
}
}
Listado 3. Código corregido
En esta ocasión, cuando ejecuté el programa el resultado fue correcto, y el tiempo de ejecución disminuyó significativamente. En lugar de los 7.40 segundos originales, ahora el ordenamiento se ejecutó en 1.60 segundos. Un vistazo al Intel Thread Checker indicó que ya no había errores ni avisos.
¡Perfecto! Afortunadamente, mi primera experiencia como profesional en la programación paralela no fue tan mala como mis memorias de manejo de threads en la universidad. Por supuesto, fue un ejemplo bastante sencillo. Sin embargo, refleja que utilizando un proceso adecuado y aprovechando las herramientas disponibles (las que mencioné en este artículo son gratuitas), hacer programas paralelos es mucho más fácil de lo que pensábamos.
El método adecuado para desarrollar programas paralelos involucra cuatro pasos:
• Análisis. Determinar los mejores lugares para usar threads
• Implementación. Introducir en el código los elementos para ejecución paralela.
• Depuración. Asegurar que todo esté funcionando correctamente.
• Optimización. Realizar ajustes para maximizar desempeño.
Este artículo abordó la implementación (a través de OpenMP) y depuración (con Intel Thread Checker). Para este pequeño programa el análisis fue automático. Sin embargo, para problemas reales, con mayor complejidad, es crítico comenzar con un buen análisis.
Referencias
[ openmp.org/wp/ ]
[ intel.com/software/products ]
[ softwarecommunity.intel.com/isn/home/ ]
[ devx.com/go-parallel ]
Al igual que la mayoría de los ingenieros de sistemas, tengo malos recuerdos de lidiar con threads en mi clase de sistemas operativos en la universidad. Así que cuando me encontré en la necesidad, ya como profesional, de aprender a hacer programas que se ejecuten en distintos threads paralelos, debo aceptar que tuve mucho miedo. Sin embargo, descubrí que actualmente hay herramientas que hacen esto mucho más sencillo de lo que pensaba.
Para reiniciarme en la programación paralela, decidí comenzar haciendo el ejercicio de implementar un ordenamiento de burbuja (bubble sort) paralelo. Éste es uno de los algoritmos de ordenamiento más sencillos y lentos. La forma en que funciona es que se recorre una lista de elementos, y se va comparando el elemento i con el i+1, y en caso de que el orden esté equivocado, se intercambia estos valores de posición. Este recorrido se repite n-1 veces (donde n es el número de elementos que contiene la lista) para asegurar que se hayan realizado los cambios necesarios y la lista está ordenada.
Decidí ordenar palabras, ya que esto me daba una forma sencilla de repartir mis datos entre distintos threads (un thread podría ordenar las palabras que comienzan con “A”, otro las que empiezan con “B”, etc.).
Al iniciar, el programa debe leer un archivo con palabras, contar cuantas palabras comienzan con cada letra (sin diferenciar entre mayúsculas y minúsculas), y guardar esta cuenta en un arreglo unidimensional de 26 elementos llamado letter_counts. Esto significa que el valor de letter_counts[0] es la cantidad de palabras que empiezan con la letra ‘a’, letter_counts[1] es la cantidad de palabras que empiezan con ‘b’, y así sucesivamente. El siguiente paso es volver a leer las palabras del archivo, y almacenarlas en un arreglo de arreglos (my_array), de acuerdo a la letra con la que empiezan. Es decir, my_array[0] apunta a un arreglo que contiene las palabras que comienzan con la letra ‘a’, my_array[1] contiene un arreglo con las palabras que comienzan con la letra ‘b’, y así sucesivamente.
Una vez que se genera este arreglo “semiordenado” –ya que las palabras se encuentran agrupadas de acuerdo a la letra con la que empiezan –, se puede invocar a la función que se encarga del ordenamiento.
Ordenamiento sin paralelismo
Primero realicé la prueba haciendo el ordenamiento de la forma tradicional, es decir sin paralelismo. El listado 1 muestra el código en lenguaje C para hacer esto.
void bubble_sort (char *** &my_array, int letter_counts[26]){
char * temp;
for (int letter =0; letter < 26; letter++) {
for (int i =0; i < letter_counts[letter] - 1 ; i++){
for (int j =0; j < letter_counts[letter] - 1 - i; j++){
if (strcmp(static_cast<char *>(my_array[letter]
[j+1]), static_cast<char *>(my_array[letter][j])) < 0){
temp = my_array[letter][j+1];
my_array[letter][j+1] = my_array[letter][j];
my_array[letter][j] = temp;
}
}
}
}
}
Listado 1. Ordenamiento sin paralelismo
El programa se ejecutó en una máquina con dos procesadores de cuatro núcleos, y al monitorear la ejecución me di cuenta que solo se usaba un núcleo. El tiempo de ejecución del programa fue de 7.4 segundos.
Implementando paralelismo
con OpenMP
Actualmente existen diversas librerías que abstraen y simplifican el manejo de threads. Una de ellas es OpenMP, la cual usé para este ejemplo. OpenMP es un API para programación paralela en C/C++ y Fortran. Es soportado por una gran variedad de compiladores incluyendo el compilador de Intel, gcc, y Visual Studio (2005 o mayor). Con OpenMP, es posible convertir un programa de un modelo single threaded a un modelo multithreaded sin necesidad de escribir un solo fork, join, o siquiera crear un thread de forma explícita. Se implementa en el código por medio de directivas “pragma”. Como programador, lo único que necesitas hacer es determinar qué patrón de paralelismo requiere tu código, y entonces indicar la directiva pragma correspondiente.
Uno de los elementos más sencillos y utilizados de OpenMP es el pragma “parallel for”. Este corresponde a lo que sería un “for” en programación single threaded. Lo que hace es dividir un ciclo de tareas en rangos, y asigna un segmento de tareas a cada procesador. OpenMP se encarga de crear los threads y asignarlos a cada procesador. En el caso de mi ejemplo, el pragma “parallel for” es justo lo que necesitaba, ya que mi algoritmo estaba estructurado en base a un ciclo maestro donde se trabaja de forma separada los distintos grupos de palabras en base a la letra con la que empiezan. Usando el parallel for a este nivel, no corría el riesgo de que dos threads accedieran el arreglo de la misma letra al mismo tiempo .El listado 2 muestra el código correspondiente, agregando el parallel for.
void parallel_bubble_sort (char *** &my_array,
int letter_counts[26]){
char * temp;
#pragma omp parallel for
for (int letter =0; letter < 26; letter++) {
for (int i =0; i < letter_counts[letter] - 1 ; i++){
for (int j =0; j < letter_counts[letter] - 1 - i; j++){
if (strcmp(static_cast<char *>(my_array[letter]
[j+1]), static_cast<char *>(my_array[letter][j])) < 0){
temp = my_array[letter][j+1];
my_array[letter][j+1] = my_array[letter][j];
my_array[letter][j] = temp;
}
}
}
}
}
Listado 2. Ordenamiento usando el parallel for
Eso fue bastante sencillo … ¿podría ser tan bello? Al ejecutar este código y monitorear el sistema me di cuenta que ya había actividad en los distintos núcleos de procesamiento. El tiempo de ejecución fue de 6.4 segundos, lo cual significó una pequeña reducción. Sin embargo, al verificar los resultados encontré que había errores ya que el arreglo no había sido ordenado correctamente. Muy probablemente esto se debía a que generé un error de data race. Un data race es cuando distintos threads acceden y modifican una misma variable de forma no coordinada; típicamente esto genera resultados erróneos en el valor de las variables.
Depurando con Intel Thread
Checker
Para encontrar el error, decidí utilizar el Intel Thread Checker. Este es un depurador para programas multithreaded. Lo que hace es monitorear la ejecución de un programa para encontrar errores como data races, deadlocks, fallas de sincronización, y tiempos de espera. La figura 1 muestra los resultados del Intel Thread Checker.
Los primeros dos errores indicaban que mis sospechas eran correctas. Al revisar las líneas referidas, noté que la línea 96 era la sentencia:
temp = my_array[letter][j+1];
y la línea 98 era:
my_array[letter][j] = temp;
Así que lo que estaba sucediendo es que distintos threads estaban recurriendo al mismo tiempo a la misma variable temp para reordenar los valores de los arreglos; también encontré warnings, indicando que había threads que esperaban más de 3 segundos para obtener acceso a un recurso, esto es bastante tiempo para un programa cuya ejecución total dura 6 segundos. Probablemente esto se debía a la pelea entre los 8 threads para acceder la misma variable temp. Ya que había encontrado el problema, tendría que pensar en la solución adecuada. Una opción era encerrar las líneas 96 a 98 en una sección crítica, o sincronizada, de forma que al mismo tiempo solamente un thread pudiera estar en esta sección, y hasta que terminara todas las operaciones de la sección liberaría el control para otro thread. Otra opción era hacer que la variable temp fuera local para cada thread.
Figura 1. Resultados del Intel Thread Checker
Esta opción me pareció mucho mejor, ya que esta variable no necesitaba ser compartida, y por medio de este mecanismo se evitó que cada thread tuviera que esperar a que los demás terminen.
Afortunadamente, en OpenMP es muy sencillo marcar variables como locales para cada thread. Simplemente se utiliza el comando private. El listado 3 muestra el código resultante.
void parallel_bubble_sort (char *** &my_array,
int letter_counts[26]){
char * temp;
#pragma omp parallel for private(temp)
for (int letter =0; letter < 26; letter++) {
for (int i =0; i < letter_counts[letter] - 1 ; i++){
for (int j =0; j < letter_counts[letter] - 1 - i; j++){
if (strcmp(static_cast<char *>(my_array[letter]
[j+1]), static_cast<char *>(my_array[letter][j])) < 0){
temp = my_array[letter][j+1];
my_array[letter][j+1] = my_array[letter][j];
my_array[letter][j] = temp;
}
}
}
}
}
Listado 3. Código corregido
En esta ocasión, cuando ejecuté el programa el resultado fue correcto, y el tiempo de ejecución disminuyó significativamente. En lugar de los 7.40 segundos originales, ahora el ordenamiento se ejecutó en 1.60 segundos. Un vistazo al Intel Thread Checker indicó que ya no había errores ni avisos.
¡Perfecto! Afortunadamente, mi primera experiencia como profesional en la programación paralela no fue tan mala como mis memorias de manejo de threads en la universidad. Por supuesto, fue un ejemplo bastante sencillo. Sin embargo, refleja que utilizando un proceso adecuado y aprovechando las herramientas disponibles (las que mencioné en este artículo son gratuitas), hacer programas paralelos es mucho más fácil de lo que pensábamos.
El método adecuado para desarrollar programas paralelos involucra cuatro pasos:
• Análisis. Determinar los mejores lugares para usar threads
• Implementación. Introducir en el código los elementos para ejecución paralela.
• Depuración. Asegurar que todo esté funcionando correctamente.
• Optimización. Realizar ajustes para maximizar desempeño.
Este artículo abordó la implementación (a través de OpenMP) y depuración (con Intel Thread Checker). Para este pequeño programa el análisis fue automático. Sin embargo, para problemas reales, con mayor complejidad, es crítico comenzar con un buen análisis.
Referencias
[ openmp.org/wp/ ]
[ intel.com/software/products ]
[ softwarecommunity.intel.com/isn/home/ ]
[ devx.com/go-parallel ]
- Log in to post comments