Published 16 years ago
(updated 14 years ago)
Cada día es más común la utilización de ambientes de Data Warehousing para apoyar la toma de decisiones dentro de las organizaciones. Sin embargo, con las tecnologías y productos relacionales, como los conocemos actualmente, están llegando al límite de su capacidad debido al gran crecimiento en los volúmenes de datos que se almacenan en los repositorios y la alta velocidad con que éstos crecen. Las
primeras manifestaciones son los altos consumos en disco, y aunque puede parecer trivial decir que el disco es barato, invito a los lectores a que soliciten a su jefe, varios Terabytes de disco y verán si es trivial o no el costo de almacenamiento.Aunado al crecimiento exponencial de los datos que se deben almacenar, la tarea de administración de las bases de datos se ha hecho sumamente compleja. Los DBAs prácticamente no duermen, para tratar de remediar los tiempos de respuesta para manejar tales cantidades de datos; ya que tienen que pasar largas horas del día y de la noche velando sus procesos y esperando que terminen. En este aspecto es común ver procesos “nocturnos” corriendo a las 10 u 11 de la mañana (invito a los lectores que revisen cuando están terminando sus procesos nocturnos), arriesgando muchas veces la apertura al público de operaciones de sus organizaciones.
Por otro lado, los tiempos de respuesta a las consultas de negocio, cada vez son más lentas con la consecuente inconformidad por parte de las áreas usuarias y la frustración de las áreas de sistemas,
porque por más esfuerzo que hacen, no logran satisfacer a sus áreas de negocio. Tomando en cuenta las anteriores premisas, es como se realizó el trabajo de investigación doctoral de un servidor y del cual
se hace una breve reseña en este artículo.
El paradigma horizontal
Desde que creamos como humanidad la computación, hemos pensado en forma horizontal.
Iniciando con las tarjetas perforadas, pasando por COBOL y hasta las bases de datos relacionales.
Siempre nos hemos basado en el concepto del registro, y así siempre se piensa en registros
horizontales que contienen por ejemplo: número de cliente, nombre, dirección, saldo, etétera.
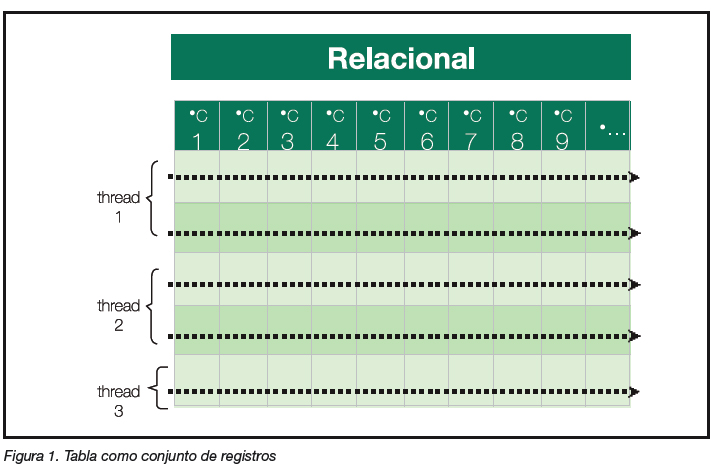
La figura 1 muestra la manera en que estructuramos archivos o tablas como un conjunto de registros horizontales, en ambientes de data warehousing. Bajo este paradigma no es raro llegar a tener tablas de 80 ó 100 columnas. Pero analicemos cómo se comportan internamente los manejadores de bases de
datos relacionales (RDBMS) para resolver una consulta de negocios sencilla, por ejemplo: “Quiero conocer el saldo promedio de los clientes”. El RDBMS lee el registro, lo pone en memoria y acumula el valor de la columna del saldo. Va por el siguiente registro y hace lo mismo, y así, hasta leer todos los registros. Lo que resulta en una gran ineficiencia, ya que se están leyendo de disco todos los campos del registro (aunque al final sólo desplieguen un campo) y en realidad son campos irrelevantes para resolver la pregunta de negocio, únicamente quiero conocer el saldo promedio, no me interesan los nombres o direcciones de los clientes. Esto repercute en una alta cantidad de operaciones de acceso a disco (que es de lo más lento) y por consecuencia, nos da esos tiempos de respuesta tan altos que tienen insatisfechos a los usuarios.
El modelo binario-relacional
¿Qué sucedería si pudiéramos ver esa tabla de clientes en forma vertical? En vez de ver un grupo de registros veríamos un grupo de columnas.
Lo que sucedería es que se podría acceder únicamente a la columna de los saldos, evitando el acceso a información irrelevante para la consulta de negocios. Esto es precisamente el cambio de paradigma que existe en las denominadas bases de datos columnares, las cuales se basan en una particularización del
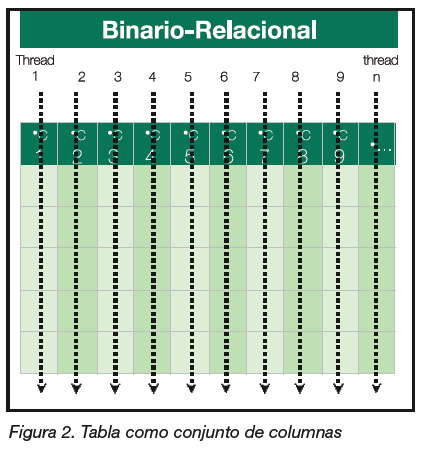
modelo relacional denominado por un servidor como el Modelo Binario-Relacional. Dicha particularización se refiere a que es un modelo relacional, pero donde todas las relaciones son de grado 2, a diferencia del modelo relacional tradicional donde las relaciones son de grado “n” (es decir, pueden tener n-atributos o campos). Por lo tanto, en el modelo binario-relacional, todas las relaciones sólo tienen una llave y un valor; viéndolo todo entonces, como si fueran columnas independientes.
En el modelo binario-relacional el servidor puede utilizar un “thread” separado por cada columna de datos, permitiendo que el procesamiento de cargas y resolución de consultas se haga en paralelo. Se refleja claramente en la figura 2.
Beneficios en almacenamiento y desempeño
El consenso tradicional indica que si uno tiene cierta cantidad de datos, al cargarlos en un RDBMS hay que considerar entre 20% y 30% de espacio adicional a lo que mida el archivo de entrada. Pero si es para un ambiente de data warehouse, entonces hay que considerar varias veces el tamaño de los datos de entrada (por los acumulados y la cantidad de índices requeridos para tratar de remediar el rendimiento); es así que, frecuentemente se calculan de 3 a 5 veces el tamaño de los datos de entrada.
¿Por qué guardar tantos valores repetidos?, ¿qué sucedería si se pudiera guardar cada valor una sola vez, eliminando duplicados; relacionando dicho valor tantas veces como sea requerido? La consecuencia lógica es que se disminuiría el tamaño del almacenamiento de datos.
Analicemos un ejemplo sencillo: en una cadena de tiendas departamentales (o cualquier otra organización), ¿cuántas facturas se generan en un año? Seguramente millones, pero pensemos que son 10 millones de facturas. Equivalente a 10 millones de fechas almacenadas, porque cada factura trae su fecha, pero sabemos que sólo existen 365 valores distintos en un año.
Esta es la segunda característica del modelo Binario-Relacional, y por tanto de las bases de datos columnares. El resultado es disminución de espacio considerable, típicamente entre 30% y 50%. El caso extremo que se logró en México con una institución gubernamental es 88% de ahorro en disco,
permitiéndole así mantener muchos más datos históricos sin sacrificar el rendimiento. De hecho, esta institución logro mejorar sus tiempos de respuesta 98% (una muestra de 128 consultas pasó de requerir 4 horas a tan solo 4 minutos). Para lograrlo se reemplazó el RDBMS tradicional por Sybase IQ. Los aplicativos no requieren cambios ya que se cuenta con interfases ODBC y JDBC y se interactúa por medio de ANSI SQL. Cifras similares se han logrado con diversas organizaciones de todos los sectores.
Las bases de datos columnares son ideales para ambientes de consultas no planeadas, ya que en cada columna se guardan valores únicos ordenados, lo que equivale a un índice, por tanto equivale a tener todas las columnas de todas las tablas indexadas, cosa que no se puede hacer en un manejador tradicional. Por lo tanto, cualquier consulta que se haga tendrá un índice que le ayudará a resolverlo rápidamente.
Conclusión
En este artículo mostramos un panorama muy breve sobre las bases de datos columnares. Para mayor
información se pueden consultar las memorias de la Conferencia Nacional Británica de Bases de Datos
(BNCOD – British Nacional Conference on Databases) de los años 2004, 2005, 2006 y 2009.
Acerca del Autor
El Dr. Víctor Gonzalez Castro es Director de Servicios Profesionales en Sybase de México. Es Ingeniero en Computación por parte de la UNAM y cuenta con estudios de Doctorado en Ciencias de la Computación con especialidad en Base de Datos por la Universidad de Heriot Watt, Reino Unido. Ha trabajado en empresas como Oracle, IBM, Probursa, Kmart, Software AG, Microstrategy y JD Edwards.
victor.gonzalez@sybase.com
primeras manifestaciones son los altos consumos en disco, y aunque puede parecer trivial decir que el disco es barato, invito a los lectores a que soliciten a su jefe, varios Terabytes de disco y verán si es trivial o no el costo de almacenamiento.Aunado al crecimiento exponencial de los datos que se deben almacenar, la tarea de administración de las bases de datos se ha hecho sumamente compleja. Los DBAs prácticamente no duermen, para tratar de remediar los tiempos de respuesta para manejar tales cantidades de datos; ya que tienen que pasar largas horas del día y de la noche velando sus procesos y esperando que terminen. En este aspecto es común ver procesos “nocturnos” corriendo a las 10 u 11 de la mañana (invito a los lectores que revisen cuando están terminando sus procesos nocturnos), arriesgando muchas veces la apertura al público de operaciones de sus organizaciones.
Por otro lado, los tiempos de respuesta a las consultas de negocio, cada vez son más lentas con la consecuente inconformidad por parte de las áreas usuarias y la frustración de las áreas de sistemas,
porque por más esfuerzo que hacen, no logran satisfacer a sus áreas de negocio. Tomando en cuenta las anteriores premisas, es como se realizó el trabajo de investigación doctoral de un servidor y del cual
se hace una breve reseña en este artículo.
El paradigma horizontal
Desde que creamos como humanidad la computación, hemos pensado en forma horizontal.
Iniciando con las tarjetas perforadas, pasando por COBOL y hasta las bases de datos relacionales.
Siempre nos hemos basado en el concepto del registro, y así siempre se piensa en registros
horizontales que contienen por ejemplo: número de cliente, nombre, dirección, saldo, etétera.
La figura 1 muestra la manera en que estructuramos archivos o tablas como un conjunto de registros horizontales, en ambientes de data warehousing. Bajo este paradigma no es raro llegar a tener tablas de 80 ó 100 columnas. Pero analicemos cómo se comportan internamente los manejadores de bases de
datos relacionales (RDBMS) para resolver una consulta de negocios sencilla, por ejemplo: “Quiero conocer el saldo promedio de los clientes”. El RDBMS lee el registro, lo pone en memoria y acumula el valor de la columna del saldo. Va por el siguiente registro y hace lo mismo, y así, hasta leer todos los registros. Lo que resulta en una gran ineficiencia, ya que se están leyendo de disco todos los campos del registro (aunque al final sólo desplieguen un campo) y en realidad son campos irrelevantes para resolver la pregunta de negocio, únicamente quiero conocer el saldo promedio, no me interesan los nombres o direcciones de los clientes. Esto repercute en una alta cantidad de operaciones de acceso a disco (que es de lo más lento) y por consecuencia, nos da esos tiempos de respuesta tan altos que tienen insatisfechos a los usuarios.
El modelo binario-relacional
¿Qué sucedería si pudiéramos ver esa tabla de clientes en forma vertical? En vez de ver un grupo de registros veríamos un grupo de columnas.
Lo que sucedería es que se podría acceder únicamente a la columna de los saldos, evitando el acceso a información irrelevante para la consulta de negocios. Esto es precisamente el cambio de paradigma que existe en las denominadas bases de datos columnares, las cuales se basan en una particularización del
modelo relacional denominado por un servidor como el Modelo Binario-Relacional. Dicha particularización se refiere a que es un modelo relacional, pero donde todas las relaciones son de grado 2, a diferencia del modelo relacional tradicional donde las relaciones son de grado “n” (es decir, pueden tener n-atributos o campos). Por lo tanto, en el modelo binario-relacional, todas las relaciones sólo tienen una llave y un valor; viéndolo todo entonces, como si fueran columnas independientes.
En el modelo binario-relacional el servidor puede utilizar un “thread” separado por cada columna de datos, permitiendo que el procesamiento de cargas y resolución de consultas se haga en paralelo. Se refleja claramente en la figura 2.
Beneficios en almacenamiento y desempeño
El consenso tradicional indica que si uno tiene cierta cantidad de datos, al cargarlos en un RDBMS hay que considerar entre 20% y 30% de espacio adicional a lo que mida el archivo de entrada. Pero si es para un ambiente de data warehouse, entonces hay que considerar varias veces el tamaño de los datos de entrada (por los acumulados y la cantidad de índices requeridos para tratar de remediar el rendimiento); es así que, frecuentemente se calculan de 3 a 5 veces el tamaño de los datos de entrada.
¿Por qué guardar tantos valores repetidos?, ¿qué sucedería si se pudiera guardar cada valor una sola vez, eliminando duplicados; relacionando dicho valor tantas veces como sea requerido? La consecuencia lógica es que se disminuiría el tamaño del almacenamiento de datos.
Analicemos un ejemplo sencillo: en una cadena de tiendas departamentales (o cualquier otra organización), ¿cuántas facturas se generan en un año? Seguramente millones, pero pensemos que son 10 millones de facturas. Equivalente a 10 millones de fechas almacenadas, porque cada factura trae su fecha, pero sabemos que sólo existen 365 valores distintos en un año.
Esta es la segunda característica del modelo Binario-Relacional, y por tanto de las bases de datos columnares. El resultado es disminución de espacio considerable, típicamente entre 30% y 50%. El caso extremo que se logró en México con una institución gubernamental es 88% de ahorro en disco,
permitiéndole así mantener muchos más datos históricos sin sacrificar el rendimiento. De hecho, esta institución logro mejorar sus tiempos de respuesta 98% (una muestra de 128 consultas pasó de requerir 4 horas a tan solo 4 minutos). Para lograrlo se reemplazó el RDBMS tradicional por Sybase IQ. Los aplicativos no requieren cambios ya que se cuenta con interfases ODBC y JDBC y se interactúa por medio de ANSI SQL. Cifras similares se han logrado con diversas organizaciones de todos los sectores.
Las bases de datos columnares son ideales para ambientes de consultas no planeadas, ya que en cada columna se guardan valores únicos ordenados, lo que equivale a un índice, por tanto equivale a tener todas las columnas de todas las tablas indexadas, cosa que no se puede hacer en un manejador tradicional. Por lo tanto, cualquier consulta que se haga tendrá un índice que le ayudará a resolverlo rápidamente.
Conclusión
En este artículo mostramos un panorama muy breve sobre las bases de datos columnares. Para mayor
información se pueden consultar las memorias de la Conferencia Nacional Británica de Bases de Datos
(BNCOD – British Nacional Conference on Databases) de los años 2004, 2005, 2006 y 2009.
Acerca del Autor
El Dr. Víctor Gonzalez Castro es Director de Servicios Profesionales en Sybase de México. Es Ingeniero en Computación por parte de la UNAM y cuenta con estudios de Doctorado en Ciencias de la Computación con especialidad en Base de Datos por la Universidad de Heriot Watt, Reino Unido. Ha trabajado en empresas como Oracle, IBM, Probursa, Kmart, Software AG, Microstrategy y JD Edwards.
victor.gonzalez@sybase.com
- Log in to post comments