Autor
En el vertiginoso mundo de la inteligencia artificial, los modelos de lenguaje de gran tamaño (LLMs) y la generación aumentada por recuperación (RAG) se han posicionado como herramientas disruptivas con un potencial enorme. Sin embargo, la promesa de interactuar conversacionalmente con nuestros datos y construir aplicaciones inteligentes no debe cegarnos ante consideraciones fundamentales que todo profesional de datos debe abordar.
Este artículo no busca desmitificar el poder de los LLMs y RAG, sino más bien ofrecer un marco de preguntas cruciales para asegurar que su implementación responda a necesidades reales y genere valor tangible.
La pregunta inicial: ¿Realmente necesitamos un LLM?
Antes de siquiera considerar arquitecturas complejas, la primera pregunta que debemos hacernos es directa: ¿nuestro caso de uso se soluciona de manera efectiva con un LLM? En muchos escenarios, las técnicas tradicionales de análisis de datos, los sistemas expertos o incluso soluciones más sencillas pueden ser más apropiadas y eficientes.
Proponemos cinco preguntas guía para discernir si un LLM es la herramienta adecuada:
- ¿Existe un componente conversacional inherente en la interacción deseada con los datos? Si la necesidad primordial es obtener respuestas directas o realizar análisis estructurados, un LLM podría ser una sobreinversión.
- ¿Requerimos fluidez conversacional en las respuestas? Más allá de la información, ¿es crucial una interacción natural y contextual?
- ¿Nuestro sistema necesita construir respuestas a partir de múltiples fuentes de datos de forma dinámica? La capacidad de integrar información diversa es una fortaleza clave de los LLMs combinados con RAG.
- ¿Se necesita creatividad en la generación de respuestas (sin sacrificar precisión)? En casos como la creación de contenido o la síntesis de ideas, los LLMs pueden aportar valor.
- ¿Es fundamental la interpretabilidad del porqué de los resultados, o simplemente queremos "platicar" con los datos? Si bien la interpretabilidad sigue siendo un desafío, comprender la trazabilidad de las respuestas es crucial en muchos contextos profesionales.
Si la respuesta afirmativa predomina en estas preguntas, entonces explorar el potencial de los LLMs y RAG se justifica.
Navegando el menú de estrategias: ¿Prompt Engineering, RAG, Fine-tuning o From Scratch?
Una vez que hemos validado la necesidad de un LLM, se abre un abanico de estrategias de implementación, cada una con sus propias características en términos de complejidad, recursos y resultados esperados:
- Prompt Engineering: Similar a "vestir" al LLM con un rol y contexto específico a través de instrucciones detalladas. Ideal para iteraciones rápidas y cuando la información requerida está dentro del conocimiento general del modelo.
- Generación Aumentada por Recuperación (RAG): Como "conectar" un plugin de conocimiento a un LLM. Permite incorporar información específica y actualizada sin necesidad de reentrenamiento completo.
- Fine-tuning: Reentrenar un modelo preexistente con un conjunto de datos específico para adaptar su comportamiento a un dominio particular. Requiere más recursos pero puede generar resultados más alineados a la tarea deseada.
- Entrenamiento From Scratch: Construir un LLM desde cero. Ofrece el máximo control pero implica una inversión masiva en recursos computacionales y experiencia.
La elección de la estrategia (o una combinación de ellas) dependerá de factores como la disponibilidad de datos especializados, la necesidad de información actualizada, el presupuesto computacional y la complejidad del caso de uso. Para empezar a generar valor rápidamente, la combinación de RAG y prompt engineering suele ser un punto de partida estratégico.
El corazón de la solución: Desafíos y consideraciones clave en la implementación de RAG
Si bien RAG ofrece un equilibrio atractivo, su implementación exitosa requiere atención a varios aspectos críticos:
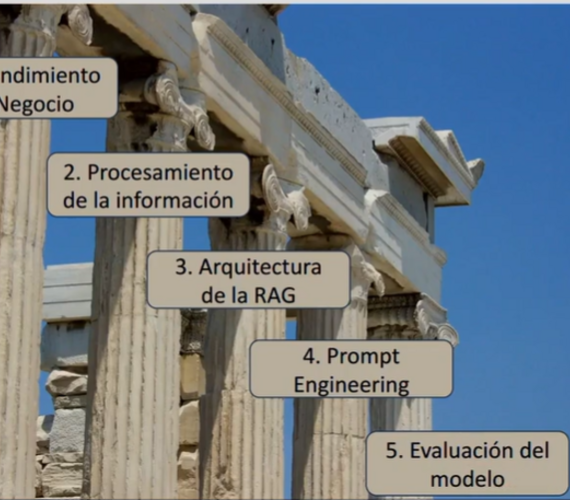
- Entendimiento profundo del negocio y el caso de uso: Al igual que en cualquier proyecto de ciencia de datos, definir el problema, el alcance y el impacto esperado es primordial. Comprender el "journey" del usuario y cómo interactuará con la aplicación RAG es esencial para diseñar una solución útil.
- Procesamiento y curación de la información: No hay atajos. La calidad de la base de conocimiento es directamente proporcional a la calidad de las respuestas. Esto implica una ingeniería de datos robusta para la segmentación (chunking), transformación y carga de la información relevante. La máxima "garbage in, garbage out" cobra especial relevancia aquí.
- Arquitectura RAG: Simple vs. avanzada: Si bien una arquitectura simple (query -> recuperación -> prompt -> LLM) es un buen punto de inicio, las arquitecturas avanzadas (pre-procesamiento de queries, búsquedas híbridas, filtrado por metadatos, post-procesamiento de documentos recuperados) pueden mejorar significativamente la precisión y relevancia de las respuestas.
- Preservación del contexto: Enriquecer los "chunks" de información con metadatos relevantes (fuente, fecha, tema, etc.) y considerar estrategias para relacionar chunks (superposición) optimiza la recuperación y proporciona un contexto más rico al LLM.
- Selección del modelo de embeddings: No existe un modelo universalmente óptimo. Experimentar con diferentes modelos de embeddings y evaluar su rendimiento en el contexto específico es crucial para una recuperación semántica efectiva.
- Prompt engineering estratégico: Un buen prompt no solo guía al LLM, sino que también puede mitigar alucinaciones, mejorar la precisión y personalizar la respuesta. Sin embargo, encontrar prompts ideales y escalables es un desafío continuo.
- Evaluación rigurosa: La evaluación no puede ser una ocurrencia tardía. Necesitamos métricas claras para definir el éxito (relevancia, precisión, coherencia, groundedness) y utilizar frameworks de evaluación (a menudo basados en otros LLMs) para optimizar el sistema. No olvidemos la validación con usuarios reales, ya que su percepción de utilidad es fundamental.
Conversación útil, no solo conversación
Los LLMs y RAG abren un mundo de posibilidades para interactuar con nuestros datos de formas innovadoras. Sin embargo, como profesionales de datos, nuestra responsabilidad radica en ir más allá del asombro inicial y abordar la implementación con un enfoque crítico y estratégico.
Plantear las preguntas correctas desde el inicio, comprender las fortalezas y limitaciones de cada estrategia y prestar atención a los detalles cruciales en la arquitectura y el procesamiento de la información son los pilares para construir aplicaciones LLM y RAG que no solo sean impresionantes, sino fundamentalmente útiles y generadoras de valor real para nuestras organizaciones. El futuro de la IA conversacional en el ámbito profesional depende de nuestra capacidad para transformar la fascinación en soluciones pragmáticas y efectivas.
¿Quieres aprender más? Mira esta charla de Data Day:
Autor
- Log in to post comments