Autor
En el dinámico y a menudo caótico entorno de una startup, la ciencia de datos emerge como un faro de conocimiento, capaz de transformar la incertidumbre en decisiones estratégicas y el crecimiento incipiente en una trayectoria ascendente. Sin embargo, la implementación efectiva de proyectos de ciencia de datos en este contexto presenta desafíos únicos, donde la velocidad, la eficiencia y la generación de valor inmediato son imperativos.
Lejos de los entornos corporativos con recursos holgados y procesos bien definidos, en una startup, el científico de datos a menudo se enfrenta a la necesidad de ser un "todólogo", navegando desde la concepción del problema hasta la puesta en producción del modelo, con la presión constante de demostrar un retorno de la inversión tangible y rápido.
Es en este escenario donde el tradicional ciclo de vida de la ciencia de datos adquiere una nueva dimensión, marcada por la iteración rápida, el conocimiento profundo del dominio, la explotación inteligente de la innovación y la elección de un stack tecnológico ágil y adaptable.
El ciclo de vida: Una telaraña de iteraciones constantes
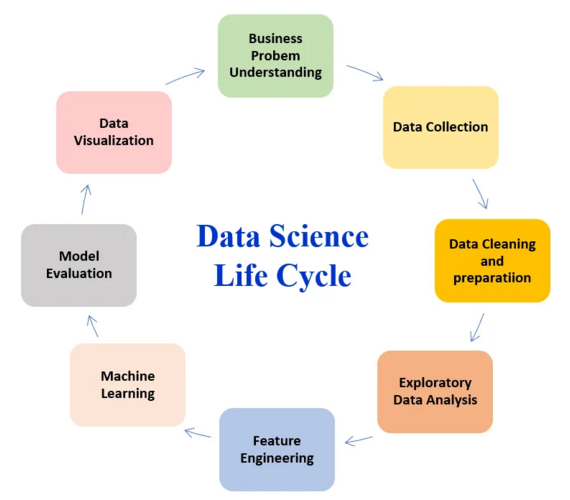
Si bien los diagramas clásicos nos presentan un flujo lineal de etapas (definición del problema, adquisición y preparación de datos, modelado, evaluación, despliegue y mantenimiento), en la práctica startup, este ciclo se asemeja más a una telaraña interactiva. La necesidad de obtener resultados en plazos ajustados impulsa a los equipos a moverse ágilmente entre estas fases, revisitando decisiones y refinando enfoques constantemente.
La definición del proyecto debe ser pragmática y enfocada en el impacto. ¿Cuál es la pregunta clave que necesitamos responder para desbloquear crecimiento o mejorar la experiencia del usuario? La familiarización con los datos se vuelve crucial, no solo desde la perspectiva técnica, sino entendiendo la historia que cuentan los datos en el contexto específico del negocio y sus desafíos particulares. Este conocimiento del dominio es un activo invaluable que permite formular hipótesis más sólidas y realizar un feature engineering más efectivo.
La prueba de concepto se erige como un hito fundamental para validar rápidamente si una idea tiene el potencial de generar valor. Aquí, la premisa es la simplicidad: un modelo baseline, aunque imperfecto, puede proporcionar información valiosa sobre la viabilidad de un enfoque y marcar la pauta para iteraciones posteriores.
El desarrollo del modelo, el lanzamiento a producción y el monitoreo no son etapas finales, sino puntos de partida para un ciclo continuo de mejora. La retroalimentación del mundo real y la evolución constante del negocio obligan a los modelos a adaptarse, lo que demanda una infraestructura flexible y herramientas que faciliten la iteración rápida.
Principios para acelerar el ciclo: Más allá de la metodología
La velocidad en el ciclo de vida de la ciencia de datos en startups no se logra únicamente adoptando metodologías ágiles; requiere la internalización de ciertos principios fundamentales:
- Enamorarse del problema, no de la solución: Es fácil caer en la tentación de aplicar el último algoritmo de moda o utilizar una técnica sofisticada, pero el verdadero valor reside en comprender profundamente el problema que se busca resolver. Este enfoque pragmático permite identificar soluciones más sencillas y efectivas en las primeras etapas.
- Iteración como mantra: El error no es un fracaso, sino una oportunidad de aprendizaje. Fomentar una cultura de experimentación constante, donde los ciclos de desarrollo e implementación sean cortos, permite identificar rápidamente qué funciona y qué no, minimizando la inversión de tiempo y recursos en callejones sin salida.
- Explotación de la Innovación adyacente: En lugar de reinventar la rueda para cada problema, las startups inteligentes buscan sinergias y reutilizan soluciones probadas en dominios adyacentes. Un modelo desarrollado para detectar un tipo de fraude puede, con las adaptaciones necesarias, aplicarse a otra tipología similar, acelerando el desarrollo y compartiendo conocimiento dentro del equipo.
- Un stack tecnológico al servicio de la agilidad: La elección de las herramientas adecuadas es un factor determinante para la velocidad del ciclo. Un buen stack tecnológico debe priorizar la facilidad de despliegue, ser agnóstico al código (para evitar el "vendor lock-in") y ser modular, permitiendo la adopción gradual de nuevas funcionalidades sin generar dependencias complejas. El objetivo es que las herramientas sirvan al equipo, y no al revés.
Un caso práctico: Preprocesamiento paralelo para un entrenamiento ágil
Para ilustrar estos principios, consideremos un caso común en startups que manejan grandes volúmenes de datos, como imágenes para verificación de identidad. Un preprocesamiento secuencial de cientos de miles de imágenes puede convertirse en un cuello de botella significativo, retrasando el entrenamiento y la iteración de los modelos.
Una solución basada en la iteración rápida y la explotación de un stack tecnológico modular podría implicar el uso de un servicio de procesamiento por lotes en la nube (como AWS Batch o Google Cloud Dataflow) para paralelizar el preprocesamiento de las imágenes. Al dividir la tarea en múltiples contenedores que se ejecutan simultáneamente, el tiempo de procesamiento se reduce drásticamente, liberando recursos y tiempo para la fase de entrenamiento y experimentación con diferentes arquitecturas e hiperparámetros.
Además, al mantener el código de preprocesamiento independiente del modelo en sí (agnosticismo al código), se facilita la experimentación con diferentes técnicas de preprocesamiento sin necesidad de modificar la lógica del modelo, y viceversa. La modularidad del stack permite incorporar herramientas de orquestación (como Dagster o Airflow) para gestionar el flujo de trabajo completo de forma eficiente y escalable.
Conclusión: Ciencia de datos como motor de crecimiento ágil
En el vertiginoso mundo de las startups, la ciencia de datos tiene el potencial de ser mucho más que un simple análisis retrospectivo; puede convertirse en un motor de crecimiento ágil y sostenible. Al adoptar un ciclo de vida flexible y centrado en la iteración rápida, al cultivar un profundo conocimiento del dominio, al explotar inteligentemente la innovación y al elegir un stack tecnológico que priorice la agilidad, las startups pueden desmitificar la complejidad de la ciencia de datos y transformarla en una ventaja competitiva invaluable. La clave reside en la capacidad de aprender rápido, adaptarse continuamente y generar valor tangible en cada iteración.
¿Quieres aprender más? Mira esta conferencia que se impartió en Data Day.
Autor
- Log in to post comments