Conferencista(s)
¿Qué es un Data Lake? ¿En dónde se utiliza un Data Lake? ¿Para qué se utiliza un Data Lake? ¿Quién utiliza un Data Lake?
Este es un mundo en ciencia de datos e ingeniería de datos cuando escuchamos hablar sobre modelos de Machine learning, AI o cuando involucra datos. Así que vamos respondiendo cada una de estas preguntas para adentrarnos al concepto de Data Lake y entenderlo de forma práctica y sencilla.
¿Qué es un datalake?
Imagina que es como un repositorio en donde vas a meter todos los datos que tienes y los que te puedas imaginar, desde imágenes, videos, textos, archivos, bases de datos, etcétera. De hecho, hasta puede caer en un data link, para que prácticamente cualquier persona, desde la analista de datos, la ingeniera de datos o inclusive la científica de datos puedan utilizar los modelos de Machine Learning. O también para llegar a tener cierta estructura para que se puedan utilizar los dashboards.
¿Cuáles son las ventajas de utilizar un Data Lake?
- Puedes meter cualquier tipo de dato. Pero, hay que tener claro los tipos de datos con los que contamos.
- Datos no estructurados. Los tipos de datos que tenemos en general son los datos no estructurados. Por ejemplo, imágenes o videos, porque básicamente no tiene tal cual una estructura en donde podamos ponerlo en una base de datos.
- Datos semiestructurados. Un ejemplo son las APIs, que tienen un formato json que si bien está medio estructurado, hay partes en las que puede que no lo esté completamente.
- Datos estructurados. Básicamente son las bases de datos porque mantiene una estructura para que podamos utilizarlos de cierta forma.
- Podemos tener infinidad de datos disponibles. Seguramente has escuchado hablar mucho de Big Data, de Machine learning o Inteligencia artificial. Con un Data Lake, podemos entrenar un modelo o proveer de datos a un programa de generación de imágenes.
- Se puede montar en la nube. Tenemos ya plataformas como AWS, Google Cloud o Microsoft Azure. Quiere decir que nosotros no necesitamos comprar servidores físicos para tener un Data Lake.
- Es escalable. Podemos escalarlo de forma horizontal. Ejemplo, si compras otra computadora y la conectores, ya no necesitas cargar todo en memoria.
- Lo pueden utilizar varias personas. Como se mencionó anteriormente, un Data Lake lo pueden utilizar desde analistas, científicas de negocio o ingenieras.
¿Cuál es la arquitectura básica de un Data Lake?
Esta es una estructura básica de un Data Lake:
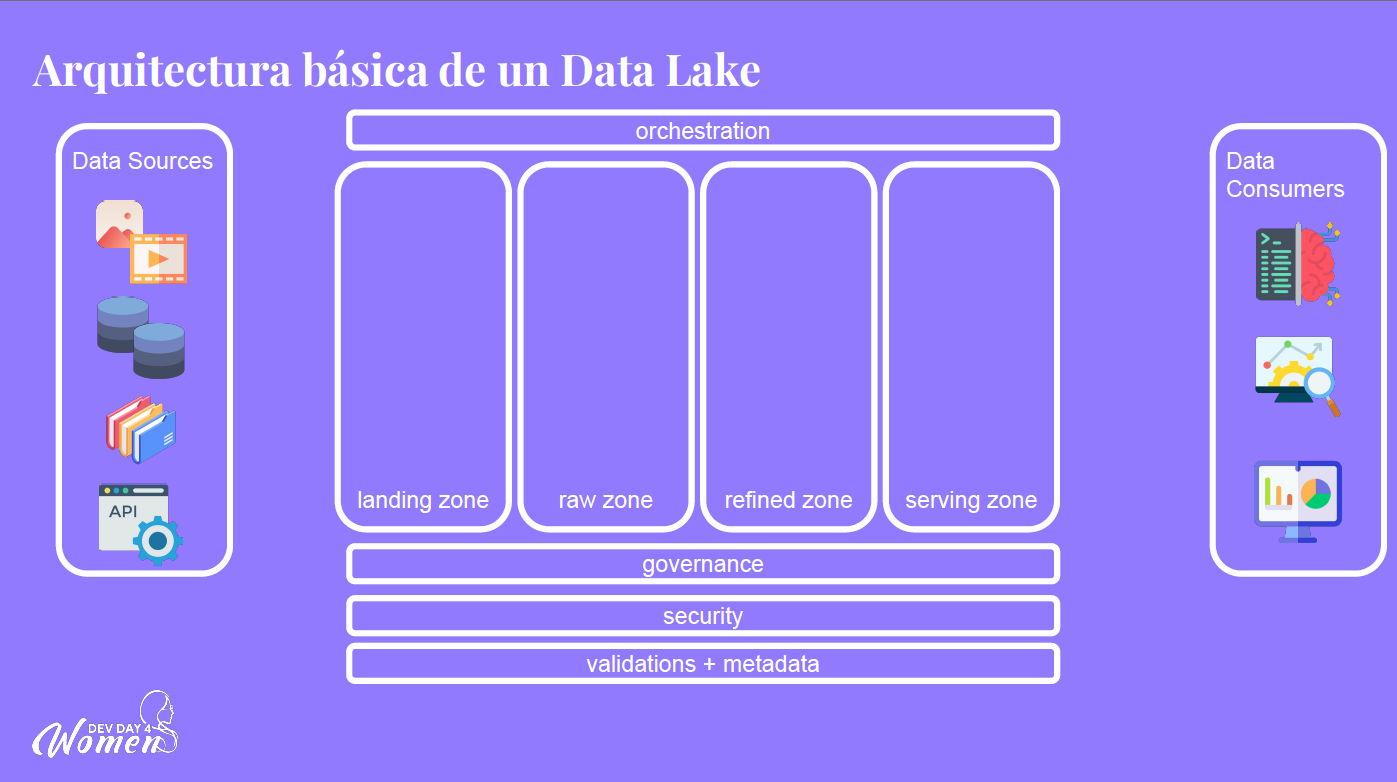
Básicamente lo que necesitamos saber desde un inicio es cuáles son nuestras fuentes de datos. Después podemos ver las cuatro capas que estas pueden utilizar de acuerdo al caso de uso.
En estas capas es donde nuestros datos van a sufrir ciertas transformaciones a lo largo de estos pasos. El pasar de una capa a otra es lo que llamamos orquestar, es decir, vamos a procesarlos teniendo un flujo, transformando los datos y acomodándolso de cierta forma.
Landing Zone.
Aquí observamos lo que se conoce como ingesta. Es decir, pasa de la fuente de datos (imágenes, bases de datos, APIs, documentos, etcétera) a ser guardado en la landing zone mediante dos métodos que son muy comunes: ETL (Extract Transform Load) y ELT (Extract Load Transform).
Raw Zone
En esta etapa los datos siguen crudos sólo que con un pequeña transformación de esquema o de formato, de acuerdo al lenguaje o herramienta que se esté utilizando.
Refined Zone
Una vez que nosotros transformamos los datos, es decir, que tenemos ese Script que ya transforma, va y lo guarda a nuestro storage. Aquí hay una capa extra que puede o no existir porque va a depender mucho de las reglas de negocio o del caso de uso del proyecto, por ejemplo.
Serving Zone
En esta última capa, si bien los datos ya sufrieron dos transformaciones, posiblemente en algún momento, la estructura termina siendo de más fácil acceso para la persona que analiza los datos, o para quien sea que se esté conectando para jalar los datos de la base. Aquí va a depender Cómo debe de estar estructurado para que sea mucho más fácil y que pueda también ser sostenible en términos de concurrencia.
En conclusión:
- El Data Lake es un repositorio de datos versátiles donde podemos meter cualquier tipo de datos estructurados, no estructurados o semiestructurados.
- Es Big Data friendly. Esto quiere decir que puede ser escalable ya que lo puedes utilizar con muchos datos.
- Si tiene un buen diseño y una buena estructura va a poder escalar
- Tiene diferentes capas y esto también depende del caso de uso
- Está diseñado para varios perfiles. Es decir, que cualquiera o muchas personas pueden consumirlo de diferentes formas
- Es el “source of true” de donde se pueden obtener datos, con la seguridad de que van a ser confiables.
Este artículo es un extracto de la conferencia "Data Lakes 101", impartida por Carolina Acosta Tovany en el evento de Dev Day 4 Women. Para conocer más a profundidad de estos conceptos, te invitamos a ver la charla completa.
¡No te pierdas más charlas como esta! Regístrate a la próxima edición de Dev Day 4 Women
En esta sesión introductoria, exploraremos los conceptos fundamentales para la construcción de un Data Lake. Desde la definición y estructura básica hasta las mejores prácticas en diseño y gestión de datos. Esta charla está diseñada para proporcionar una base sólida a aquellas personas que desean adentrarse en el mundo de los Data Lakes.
Abordaremos temas como la ingestión de datos, capas y transformaciones, así como la escalabilidad para un Data Lake exitoso. Al finalizar, contarás con los conocimientos esenciales para iniciar su propio proyecto de Data Lake o mejorar sus habilidades existentes en este campo crucial de la gestión de datos.