Publicado en
Autor
En la edición anterior describimos y mostramos un ejemplo en el cual una mala estimación puede ocasionar desde problemas de negociación hasta problemas económicos por tener que absorber costos no planeados. Esta situación es bastante común en la industria. De hecho, de 49 organizaciones que yo he entrevistado, tanto consultoras de software como corporativos e instituciones públicas, solamente 3 (6%) me han manifestado la ausencia de problemas en el tema relativo a las estimaciones.
A pesar de que ya conocemos el problema que implica la falta de información en etapas tempranas de los proyectos (la mayoría de las variables son subjetivas, no hay mucho que contar) y que sabemos que el método más utilizado porque mejor se acopla a esa realidad es el “juicio de experto”, el problema sigue existiendo, ¿por qué?
Esta pregunta no es sencilla pero en parte se debe a que la ingeniería de software es relativamente joven comparada con otras ingenierías. También tiene que ver con que la gente cree que el software es más intelectual que físico y por esto no se puede medir. Difiero con esto porque si no tenemos qué medir, entonces no podemos hacer ingeniería, lo que hacemos es arte. Y el problema con hacer arte es que los resultados dependen por completo de tener buenos artistas y no es algo sustentable.
La IEEE define ingeniería de software como; “La aplicación de una estrategia sistemática, disciplinada y cuantificable, al desarrollo, operación y mantenimiento de software; es decir, la aplicación de ingeniería al software”.
Entonces, para hacer ingeniería necesitamos medir. Si la mayoría de las variables que tenemos son cualitativas entonces necesitamos un mecanismo para medir este tipo de variables. Esta situación ha sido detectada y estudiada por varias personas, algunas de las cuales han encontrado en la Lógica Difusa un apoyo para trabajar mejor con estas variables [2,3], ya que estos modelos son diseñados típicamente sobre la base de reconocidos expertos que identifican e intuitivamente cuantifican las entradas con valores lingüísticos para inferir la variable dependiente.
Se han realizado a nivel científico varios estudios que demuestran que en comparaciones contra los métodos tradicionales utilizados para generar modelos de estimación como regresión lineal, redes neuronales, etc., los basados en lógica difusa han presentado ventajas en las capacidades de modelado.
Existe un modelo que cubre estos requisitos además de un estudio formal muy extenso, es mexicano y se denomina Estimación de Proyectos en Entornos de Incertidumbre (EPEI), el problema del proyecto descrito en el número anterior se evaluó con este modelo y se presentan a continuación el proceso y los resultados.
Configuración del Modelo. Se reunió a los participantes en la estimación original del proyecto, los roles que participaron fueron: Gerente de Procesos y Calidad, Gerente de Administración de Proyectos, Consultor en Procesos, Director de Administración de Proyectos, Director de Tecnología y Calidad. La configuración y generación de siete escenarios distintos llevó aproximadamente 2 horas.
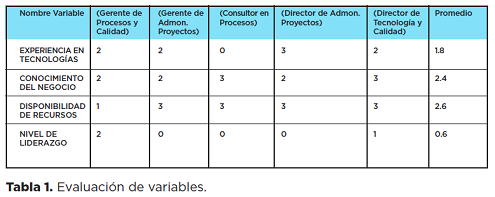
Variables de Entrada. A estas personas se les pidió que identificaran las variables que afectaron mayormente al resultado del proyecto. Las variables identificadas fueron: Experiencia en tecnologías, conocimiento del negocio, disponibilidad de recursos, nivel de liderazgo.
Variable de Salida. Para la variable de salida ellos definieron que sus proyectos iban del rango de 2 meses hasta 36 meses, ya que les interesaba estimar duración. Para la parte de estimación de esfuerzo ellos utilizaban la tabla mostrada en la figura 1. Sin embargo, esta tabla de esfuerzos no representa la realidad ya que una sola hora puede ser la diferencia entre un proyecto pequeño y uno mediano, o uno mediano y uno grande. El modelo EPEI utilizó algo que representa mejor la variable de salida que es una función como la que se muestra en la figura 2 con rango de 2 a 36 meses para duración y con rango de 500 a 19000 horas para esfuerzo.
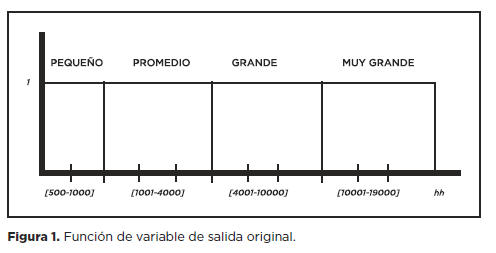
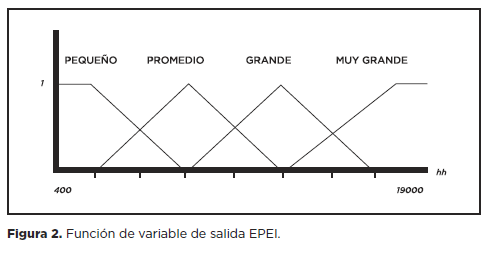
Este enfoque del modelo es muy relevante ya que trabaja en función de precisión de significado, esto es que se entiende que un proyecto conforme deja de ser Pequeño, empieza a ser Promedio, y conforme deja de ser Promedio empieza a ser Grande, de hecho en algún momento puede pertenecer a dos valores al mismo tiempo, es decir, un proyecto pareciera ser entre Promedio y Grande. Este enfoque de manejo de variables sin duda refleja de mejor manera la realidad que el manejo de rangos.
Reglas de Inferencia. Al grupo de expertos se les pidió que definieran la relación de las distintas variables de entrada que definieron en función de la variable de salida del proyecto en base a reglas “If…then”, generando con esto un motor de inferencia propio para la organización ya que representa el conocimiento de sus expertos.
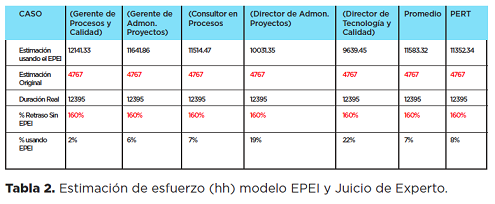
Resultados obtenidos. A los expertos que participaron en la estimación original y en la configuración del modelo se les pidió que evaluaran las variables de entrada en el rango definido (de 0 a 5). Con estos valores se generaron distintos escenarios, uno para cada participante, se obtuvo el promedio de los valores asignados a cada variable y se obtuvo un escenario promedio, ya con los datos se obtuvo un escenario PERT ([O-P]/6).
La evaluación de las variables se utilizó tanto para estimar la duración como el esfuerzo. En las tablas 1 y 2 se muestran la evaluación de las variables y los resultados obtenidos.
Conclusiones
Se ha mostrado en las dos partes de este artículo que existe un problema vigente para la estimación de proyectos de software en etapas tempranas. Al mismo tiempo se ha propuesto el uso de un modelo novedoso que permite realizar estas estimaciones con un enfoque de ingeniería incluso cuando la mayoría de las variables son cualitativas.
El modelo presenta una posible solución con varias ventajas, entre las que se encuentran que la experiencia pasa a ser un activo de la organización ya que se almacena en una base de datos basada en inferencias definidas por los expertos y que permite que la experiencia sea replicada sistemáticamente, ya que una vez definida la base de conocimiento las estimaciones pueden ser realizadas por otras personas, conservando el principio de las mediciones que deben de ser realizadas con el mismo instrumento para poder compararse, lo que no es posible realizar con juicio de experto.
El uso de este modelo nos habilitaría a realizar ingeniería incluso tomando como base el juicio de experto, al permitir realizar el enfoque cuantificable aún en etapas tempranas del desarrollo de software.
Francisco Valdés Souto es Candidato a PhD. en Ingeniería de Software con especialización en medición y estimación de software Universidad de Quebéc en École de Technologie Supérieure. Certified ScrumMaster (CSM). Project Manager Professional (PMP). Primer mexicano certificado como COSMIC FFP Size Measurer por el COMMON SOFTWARE MEASUREMENT INTERNATIONAL CONSORTIUM (COSMIC). Es socio de SPINGERE, empresa especializada en servicios de dimensionamiento y estimación de software. @valdessoutofco
- Log in to post comments