Publicado en
Autor
Apache Spark es un framework open source para el procesamiento de datos masivos diseñado con tres prioridades en mente: velocidad, facilidad de uso, y capacidades avanzadas de analítica.
Spark está cobrando gran popularidad porque viene a resolver varias de las limitaciones inherentes de Hadoop y MapReduce. Spark puede utilizarse junto con Hadoop, pero no es requisito. Spark extiende el modelo MapReduce para hacerlo más rápido y habilitar más escenarios de análisis, como por ejemplo queries interactivos y procesamiento de flujos en tiempo real. Esto es posible ya que Spark usa un cluster de cómputo en memoria (in-memory).
Uno de los elementos clave de Spark es su capacidad para procesamiento continuo (stream processing). Esto se logra por medio del componente Spark Streaming. En este artículo brindamos un vistazo de cómo funciona Spark Streaming.
Descripción general
Spark Streaming puede ingerir datos de un amplio de fuentes, incluyendo flujos provenientes de Apache Kafka, Apache Flume, Amazon Kinesis y Twitter, así como de sensores y dispositivos conectados por medio de sockets TCP. También se pueden procesar datos almacenados en sistemas de archivos como HDFS o Amazon S3.
Spark Streaming puede procesar datos utilizando una variedad de algoritmos y funciones tales como map, reduce, join y window. Una vez procesados, los datos son enviados a archivos en file systems o para popular dashboards en tiempo real.
A grandes rasgos, lo que hace Spark Streaming es tomar un flujo de datos continuo y convertirlo en un flujo discreto —llamado DStream— formado por paquetes de datos. Internamente, lo que sucede es que Spark Streaming almacena y procesa estos datos como una secuencia de RDDs (Resilient Distributed Data). Un RDD es una colección de datos particionada (distribuida) e inmutable. Es la unidad de información que el motor de procesamiento de Spark (Spark Core) tradicionalmente consume. Así que cuando usamos Spark Streaming para alimentar un stream a Spark Core, éste último los analiza de forma normal, sin enterarse de que está procesando un flujo de datos, porque el trabajo de crear y coordinar los RDDs lo realiza Spark Streaming.

Figura 1. Spark Streaming prepara un flujo para que Spark Core lo pueda consumir.

Figura 2. Spark Streaming genera RDDs por intervalos de tiempo.
Orquestación del cluster
La figura 3 muestra a grandes rasgos cómo opera la orquestación del cluster. Las actividades son orquestadas por un programa conocido como Driver. Este programa típicamente instancía a SparkContext para realizar la orquestación de los procesos ejecutores, que son los que operan sobre los datos.
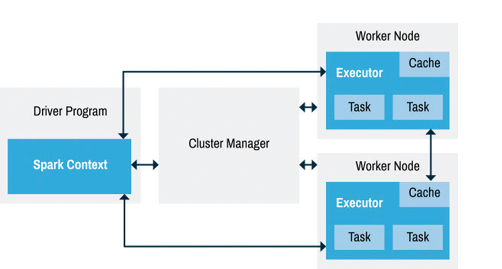
Figura 3. El driver orquesta el cluster de procesamiento.
En el caso de aplicaciones basadas en streams, se utiliza StreamingContext en lugar de SparkContext, ya que StreamingContext soporta DStreams.
Como podemos ver, el Driver es un punto central de operación, así que es importante mitigar las posibilidades de que falle. Spark Streaming soporta un concepto llamado “checkpointing” que asegura que todos los datos y metadatos asociados con RDDs que forman flujos de datos son replicados continuamente a un almacenamiento tolerante a fallas. Esto permite que en caso de una falla del driver se puedan recuperar y procesar el flujo de datos.
Modelos de procesamiento
Spark Streaming soporta distintos modelos correspondientes a las semánticas típicamente utilizadas para el procesamiento de flujos. Esto asegura que el sistema entrega resultados confiables, aún en caso de fallas en nodos. Los flujos de datos pueden ser procesados de acuerdo a los siguientes modelos:
- Exactamente una vez (exactly once). Cada elemento es procesado una sola vez.
- A lo más una vez (at most once). Cada elemento puede ser procesado máximo una vez, y es posible que no sea procesado.
- Por lo menos una vez (at least once): Cada elemento debe ser procesado por lo menos una vez. Esto aumenta la posibilidad de que no se pierdan datos pero también es posible que se generen duplicados.
No todos estos modelos son soportados con todos los tipos de fuentes de datos. Es necesario verificar cuáles semánticas se soportan en cada una.
Desde un punto de vista de procesamiento, el modelo más sencillo de construir es “at most once”. Lo que implica este escenario es que es aceptable que ocasionalmente haya pérdida de datos, ya que lo que más importa es mantener la continuidad del flujo. Pensemos en cómo funciona un stream de video: de vez en cuando se pierden paquetes de información y baja un poco la calidad, pero lo importante es que se mantenga el flujo y que no tengamos que comenzar desde el inicio.
Bajo un modelo “at least once”, tenemos la garantía de que aunque haya alguna falla en algún nodo, no perderemos datos ya que cuando el nodo se recupere (o se reasigne su carga a otro) éste procesará todos los datos para asegurar que no se le vaya ninguno. Trasladando esto a nuestro ejemplo de streaming de un video, lo que sucedería es que todos los datos con buena calidad pero corremos el riesgo de que se repitan pedazos que ya habíamos visto. Al usar este modelo debemos buscar que las operaciones en nuestro código sean idempotentes, es decir que siempre produzcan el mismo resultado sin importar si han sido ejecutadas anteriormente (por ejemplo, x = 4 es idempotente pero x++ no lo es). De esta manera, no importa si procesamos un dato varias veces, ya que en ambas ocasiones nos generará el mismo resultado y podemos filtrar en base a esto.
Aunque el modelo “exactly once” es lo que parecería lógico que siempre debamos escoger, en realidad no es necesario en todas las ocasiones y hay que tener cuidado al escogerlo. Debemos entender que este modelo es el más intensivo en recursos y puede ocasionarnos problemas de desempeño debido a todo el procesamiento adicional que se requiere para asegurar que cada uno de los datos no se pierda ni se duplique. Adicionalmente, si nuestro código es idempotente, con un modelo at least once tendremos resultados confiables.
Consecuencias de micro-batches
Como ya vimos, estrictamente Spark Streaming no opera en base a flujos continuos sino a micro-batches que tienen un tiempo de intervalo entre ellos (típicamente de menos de 5 segundos). Es importante que entendamos las consecuencias que esto puede tener. Por un lado, se puede configurar y reducir el intervalo a menos de un segundo, lo cual nos daría un desempeño casi de tiempo real, pero con un alto costo en recursos de procesamiento. Adicionalmente, un argumento en contra del esquema de micro-batches es que puede ser que los datos no se reciban en el orden exacto en el que sucedieron. Esto puede o no ser relevante dependiendo de la aplicación específica. Por ejemplo, en un timeline de Twitter tal vez no sea indispensable que los tweets sean procesados exactamente en el mismo orden en el que fueron generados.
Referencias
- J. Scott. “A Quick Guide to Spark Streaming”. http://swgu.ru/rf
- Log in to post comments