Publicado en
Autor
Los buscadores de Google, World of Warcraft, Seti@Home, Bitcoin, Windows Azure tienen algo en común: son sistemas distribuidos. A pesar de utilizarse en sistemas con propósitos tan distintos, comparten ciertas características. En este artículo veremos la teoría y las bases para construir un sencillo motor de búsqueda distribuido.
Antes de entrar de lleno a nuestro buscador, necesitamos conocer un poco de teoría para entender las características de este tipo de sistemas, así como lo necesario para construirlos.
¿Qué es un sistema distribuido?
Un sistema distribuido es un sistema de software cuyos componentes están separados físicamente y conectados entre sí por una red de computadoras, se comunican y coordinan entre ellos pasando mensajes. Dichos componentes interactúan entre ellos para lograr una meta común.
Las tres características principales de un sistema distribuido son:
-
Concurrencia de componentes: Los componentes pueden ejecutar sus acciones de manera concurrente e independiente.
-
No hay un reloj global: Los componentes (nodos) de un sistema distribuido no dependen de un reloj que sincronice o indique las acciones de los distintos nodos.
-
Falla independiente de componentes: La falla de un componente no afecta al resto de los componentes.
Para comunicar los nodos de un sistema distribuido es necesario un middleware; es decir, un software que proporciona un enlace entre programas independientes. Hay distintos tipos de middleware, pero en este caso nos enfocaremos en middleware orientado a mensajes (MOM). Los dos modelos de mensajeo más comunes y soportados por la mayoría de los sistemas de mensajeo son:
-
Publish-Subscribe (pub/sub) – Los emisores (publishers) no envían mensajes directamente a receptores (suscriptores) específicos, sino que simplemente etiquetan su mensaje con una o más categorías y lo publican, ignorando si hay o no suscriptores recibiendo los mensajes de dicha(s) categoría(s). De manera similar, los suscriptores se suscriben a categorías ignorando si hay emisores publicando mensajes en ellas.
-
Cola de Mensajes: El publicador envía mensajes a una cola donde son guardados hasta que el receptor los recibe, los mensajes pueden expirar después de cierto tiempo. A diferencia de publish–subscribe, en la cola de mensajes el receptor del mensaje activamente tiene que ir a la cola y buscar por nuevos mensajes.
Nuestro motor de búsqueda usará el patrón publish–subscribe. La principal ventaja de este modelo es que genera bajo acoplamiento, ya que los publicadores y suscriptores no necesitan conocer la existencia unos de otros, y por lo tanto pueden operar independientemente. Al tener bajo acoplamiento, este modelo es más fácil de escalar horizontalmente. En cuanto a las desventajas del modelo, hay que tener en cuenta que nos obliga a tener bien definida la estructura de datos a publicar, y que los suscriptores tengan conocimiento de ella. Es así que si cambia la estructura de datos, hay que modificar tanto al publicador como al subscriptor. Mantener compatibilidad con distintas versiones no es fácil, es más sencillo lanzar nuevos eventos que usen las nuevas versiones de la estructura de datos y crear nuevos subscriptores que escuchen a dichos eventos. Otro inconveniente a tener en cuenta es que dado que el publicador no sabe si hay o no subscriptores, el middleware que distribuye los mensajes debe tener mecanismos que garanticen, en la medida de lo posible, la entrega de dichos mensajes.
El motor de búsqueda
El objetivo de este artículo es plantear y resolver un escenario sencillo que pueda ser usado como base para desarrollar un buscador más robusto o incluso cualquier sistema distribuido. Siendo así, nuestro motor de búsqueda se encargará de buscar una palabra en archivos de texto que estén localizados en distintas computadoras. Desde una aplicación web publicaremos eventos para lanzar la búsqueda, distintos nodos estarán escuchando por esos eventos y buscarán dicha palabra en el contenido de todos los archivos de texto en una ruta específica; como resultado, los nodos regresarán el nombre del archivo donde encontró la palabra y el número de línea donde fue encontrado. La figura 1 ilustra el comportamiento del buscador. El proceso es el siguiente:
-
El browser publica un evento de búsqueda con el término a buscar.
-
El middleware informa a los suscriptores el evento de búsqueda les envía el término a buscar.
-
Cada suscriptor itera sobre los archivos de texto locales buscando el término.
-
Cada suscriptor publica un evento con los resultados de su búsqueda.
-
El browser a su vez, es suscriptor del evento “resultados”, así que por cada conjunto de resultados el middleware le avisa al browser y le provee dichos resultados.
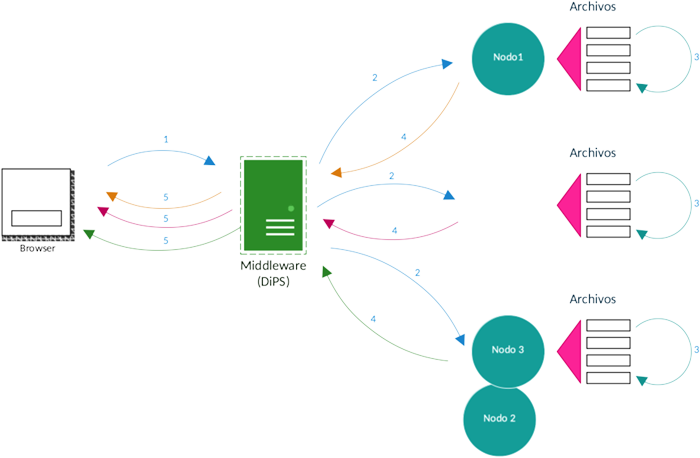
Figura 1.
Siendo que cada nodo es independiente, que no necesitan sincronizarse entre ellos con un reloj y que las búsquedas en cada nodo pueden ejecutarse de manera simultánea, nuestro motor de búsqueda cumple con las tres características principales de un sistema distribuido.
DiPS como middleware
Antes de empezar a desarrollar el motor de búsqueda debemos escoger el middleware que usaremos. Hay varias opciones como RabbitMQ, Websphere MQ, Microsoft Message Queue Server, todos ellos muy conocidos y estables pero basados en colas (queues). Nosotros queremos queremos usar el patrón publish–subscribe por lo que usaremos un servicio que aún está en fase alpha llamado DiPS (Distributed Publish Subscribe), que se puede descargar en http://pedro-ramirez-suarez.github.io/DiPS/
Otra razón por la que usaremos DiPS, es porque hay clientes disponibles para .Net (100% compatible con Mono), Javascript y Ruby. Desarrollaremos nodos buscadores en .Net y en Ruby.
Conectarse con DiPS es muy sencillo:
Listado 1. Conexión a DiPS
Desarrollando el buscador
Habiendo elegido el middleware a usar, necesitamos definir los distintos componentes que debemos implementar como parte de nuestra solución. El listado 2 muestra los distintos pedazos de código que utilizaremos.
- Lo primero que necesitamos es definir las entidades que representen los datos de nuestro término de búsqueda, así como los resultados de dicha búsqueda. Para esto usaremos las clases SearchWord y SearchWordResult. La primera representa el término de búsqueda y la segunda representa una ocurrencia encontrada del término en cuestión, indicando en qué documento y línea se encontró la palabra, así como el texto de dicha línea. Un agente de búsqueda regresaría una lista con 0 a n elementos de esta entidad.
- A continuación requerimos definir el código de los suscriptores. Es decir, los agentes que reciben una petición de búsqueda, la ejecutan y regresan una lista de resultados. Program.cs muestra el esqueleto del código que usaría un suscriptor para recibir una petición de búsqueda y realizarla localmente.
- El último paso es desplegar los resultados en un navegador web los resultados de los distintos suscriptores (que al enviar resultados se convierten en publicadores). Index.cshtml muestra un ejemplo en ASP.Net de cómo se podrían recibir y desplegar dichos resultados.
Todo el código fuente del motor de búsqueda, así como otros ejemplos de cómo usar DiPS para desarrollar un chat o el back end de una aplicación web pueden encontrarse en https://github.com/pedro-ramirez-suarez/DiPSClientSample
Adicionalmente, en https://www.youtube.com/watch?v=2rrBOsE61ZE pueden ver una demostración de cómo funciona.
Puntos a mejorar
Los resultados de cada nodo podrían primero preprocesarse antes de ser enviados al proceso que lanzó la búsqueda. De esta manera podríamos hacer cosas como ordenarlos alfabéticamente o por alguna otra clasificación. El motor de búsqueda tampoco implementa un modelo de programación MapReduce, ni organiza, mantiene o busca el contenido de los archivos de texto de manera que las búsquedas sean más eficientes.
DiPS está bien para experimentar y aprender, pero aún no es un servicio maduro, no recomendaría usarlo en aplicaciones críticas.
Lo que aprendimos aquí, podemos aplicarlo a cualquier tipo de sistema distribuido, solo es cuestión de separar la funcionalidad en componentes que puedan correr de manera independiente, por ejemplo, podríamos desarrollar un PaaS creando componentes que administren y monitoreen bases de datos, otros para administrar y monitorear servidores web, dns, etc., para resolver problemas científicos que requieran mucho poder de cálculo, podríamos separar los datos y los cálculos necesarios en distintos procesos que correrían en distintos nodos. Una vez que aprendemos las bases y empezamos a pensar desde el punto de vista de un sistema distribuido, empezamos a ver muchas oportunidades de aplicación.
Chief Architect en Scio Consulting, líder y colaborador en varios proyectos open source en distintos lenguajes, siempre aprendiendo y buscando nuevas formas de usar la tecnología. https://github.com/pedro-ramirez-suarez pramirez@sciodev.com
- Log in to post comments