Publicado en
Autor
Hoy en día, Internet, la red mundial de información, es plana. Dentro de algún tiempo, no lo será más. Esta es la promesa de la web 3.0, internet con significado o simplemente web semántica. A continuación, vamos a explicar en qué consiste esta tendencia, los retos a los que se enfrenta y su trascendencia para el futuro de Internet.
Pasado y presente de Internet
Rastrear todas las raíces de Internet nos llevaría por distintos caminos y a diferentes épocas del siglo pasado; sin embargo no hay duda de que la invención del lenguaje HTML y del protocolo HTTP fueron determinantes en su vertiginoso desarrollo.
Detrás de estos y otros avances tecnológicos ha estado quien es mundialmente reconocido como el “padre de Internet”, el científico inglés Tim Berners-Lee, quien ideó los principios de lo que sería la World Wide Web (WWW), apenas iniciada la década de 1990. De entonces a la fecha, Internet ha dado lugar a una proliferación inaudita de documentos disponibles a través de la red.
El legado es indudable: los seres humanos tenemos acceso a millones y millones de recursos de información, así como una comunicación prácticamente con todo el mundo, en cualquier momento y a un bajo costo.
1… 2… 3… Web
Quienes han estudiado a detalle el proceso evolutivo de Internet separan las etapas de su desarrollo en tres periodos no necesariamente fijos en el tiempo sino caracterizados por el potencial de que son capaces cada uno de ellos.
La llamada Web 1.0 o primera versión de internet se refiere a una red “informativa”, es decir aquella que permite a los internautas la lectura de documentos electrónicos. Al menos hasta su primera década de vida, así era Internet: un medio unidireccional de comunicación virtual, enfocado en la digitalización de textos para su lectura desde navegadores en computadoras personales.
A medida que las necesidades de los usuarios aumentaron y los avances tecnológicos lo permitieron, Internet se transformó en una red bidireccional o “colaborativa”, que también es conocida como web social o Web 2.0. En ella, la verticalidad en los flujos de información le está cediendo el paso a retroalimentaciones directas de los lectores con respecto a los contenidos de los sitios. Si la red anterior era una red para leer, ésta otra es para leer y escribir, porque en ella los usuarios ya no juegan un rol pasivo como simples receptores de información, sino uno activo que los convierte también en autores y agregadores de información. La filosofía detrás de este paradigma es que la inteligencia colectiva es mucho más robusta y eficiente que el conocimiento individual.
La web que seguirá, en cambio, se propone un salto cualitativamente distinto. La web 3.0 pretende ser “inteligente” y saber qué hacer con tanta información. El Internet, que primero fue informativo y luego colaborativo, se prepara ahora para ser semántico y entender el significado de sitios, páginas, documentos y todo recurso de información disponible en la red.
Cantidad que no es calidad
Internet crece día con día pero aún no es capaz de tomar sus propias decisiones. Es todavía un menor de edad que no sabe qué sabe. Además es obeso, desorganizado y, si nos ponemos exigentes, bastante tonto. Es cierto que nos ha dado muchas satisfacciones y ninguna otra tecnología se le compara en alcance y potencial de transformación social, pero ya va siendo hora de que aprenda a hacer algo más. Lo que al principio era una bondad de Internet, empieza a revertirse, y si no hacemos algo nos caerá encima cual torre de Babel. Nos referimos a la facilidad para publicar información en la web y a su contraparte para buscarla y encontrarla rápida y eficientemente. Ya se percibe una sobrecarga de información electrónica, prevalece una heterogeneidad enorme de las fuentes de información y, en consecuencia, hay brechas de interoperabilidad casi infranqueables. No hay capacidad humana que salga bien librada de esta problemática y es por ello que, desde la disciplina de la inteligencia artificial, ha salido en nuestra ayuda este novedoso concepto de web semántica, que a continuación exploramos con mayor detalle.
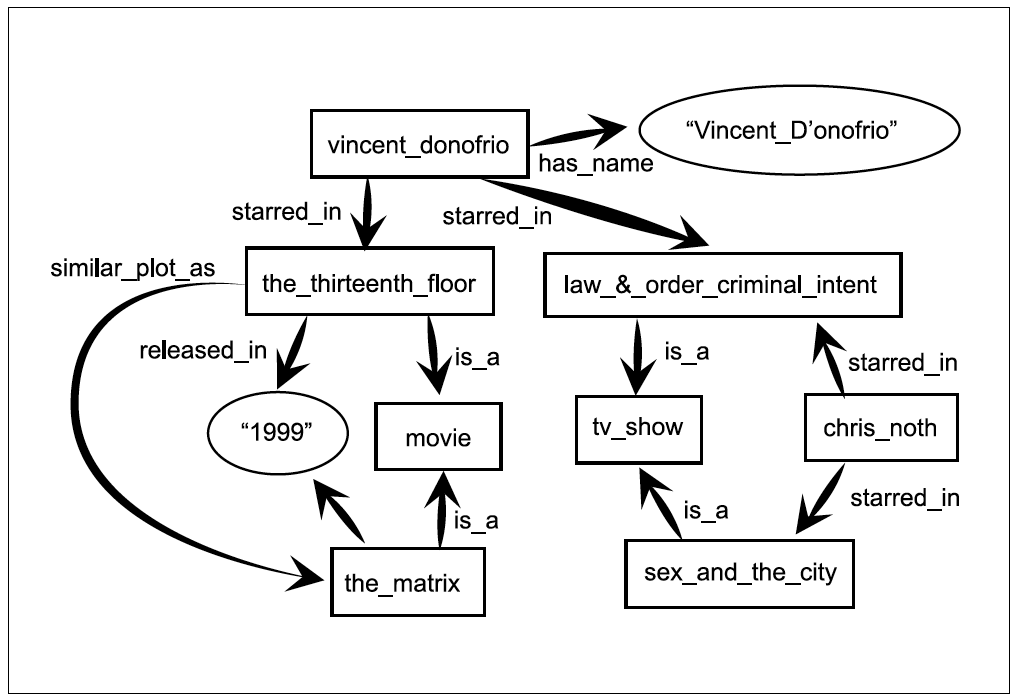
Figura 1. Ejemplo de un modelo RDF.
La web con significado
El principal impulsor y conceptualizador de la web semántica es el mismo “padre de internet”, Tim Berners-Lee, de quien ya hablamos líneas arriba. Él define a la web semántica como: “una red extendida, dotada de mayor significado, en la que cualquier usuario en Internet podrá encontrar respuestas a sus preguntas de forma más rápida y sencilla, gracias a una información mejor definida. Al dotar a la web de más significado y, por lo tanto, de más semántica, se pueden obtener soluciones a problemas habituales en la búsqueda de información”.[1]
La propuesta consiste en facultar a la próxima generación de sistemas de información para procesar el contenido de las páginas web, así como razonar, deducir e inferir sobre ellas en forma automática, ya sea para resolver problemas o contestar preguntas cotidianas de los seres humanos. Para que esto sea posible, resulta imprescindible construir una web con contenido estructurado, que incorpore metadatos semánticos para su descripción, así como una ontología que establezca su significado y determine sus relaciones involucradas.
Vale la pena comentar que un primer paso en la vía de la web semántica es precisamente el desarrollo de lo que se ha dado en llamar la “data web”, que es una fase previa durante la cual se pretende homologar los formatos de publicación en internet y, por lo tanto, permitir un nuevo nivel de integración de datos y aplicaciones interoperables.
Componentes de la web semántica
La web semántica se apoya en tecnologías y estándares que le permiten avanzar en el objetivo de integrar una infraestructura global que permita compartir y reutilizar datos y documentos entre diferentes aplicaciones y usuarios. Dichos componentes son los siguientes:
- RDF (Resource Description Framework). Es un modelo de datos que representa recursos y las relaciones que se puedan establecer entre ellos, proporcionando información descriptiva simple sobre cada recurso. El elemento de construcción básica en RDF es el “triple” o sentencia, que consiste en dos nodos (sujeto y objeto) unidos por un arco (predicado), donde los nodos representan recursos y los arcos propiedades.
- SPARQL (Protocol and RDF Query Language). Es un lenguaje de consulta sobre RDF que permite hacer búsquedas sobre los recursos de la web semántica utilizando distintas fuentes de datos.
- OWL (Ontology Web Language). Es un mecanismo para desarrollar temas o vocabularios específicos en los cuales se asocian los recursos. Lo que hace OWL es proporcionar un lenguaje para definir ontologías estructuradas que pueden ser utilizadas a través de diferentes sistemas. Las ontologías incluyen definiciones de conceptos básicos en un campo determinado y la relación entre ellos.
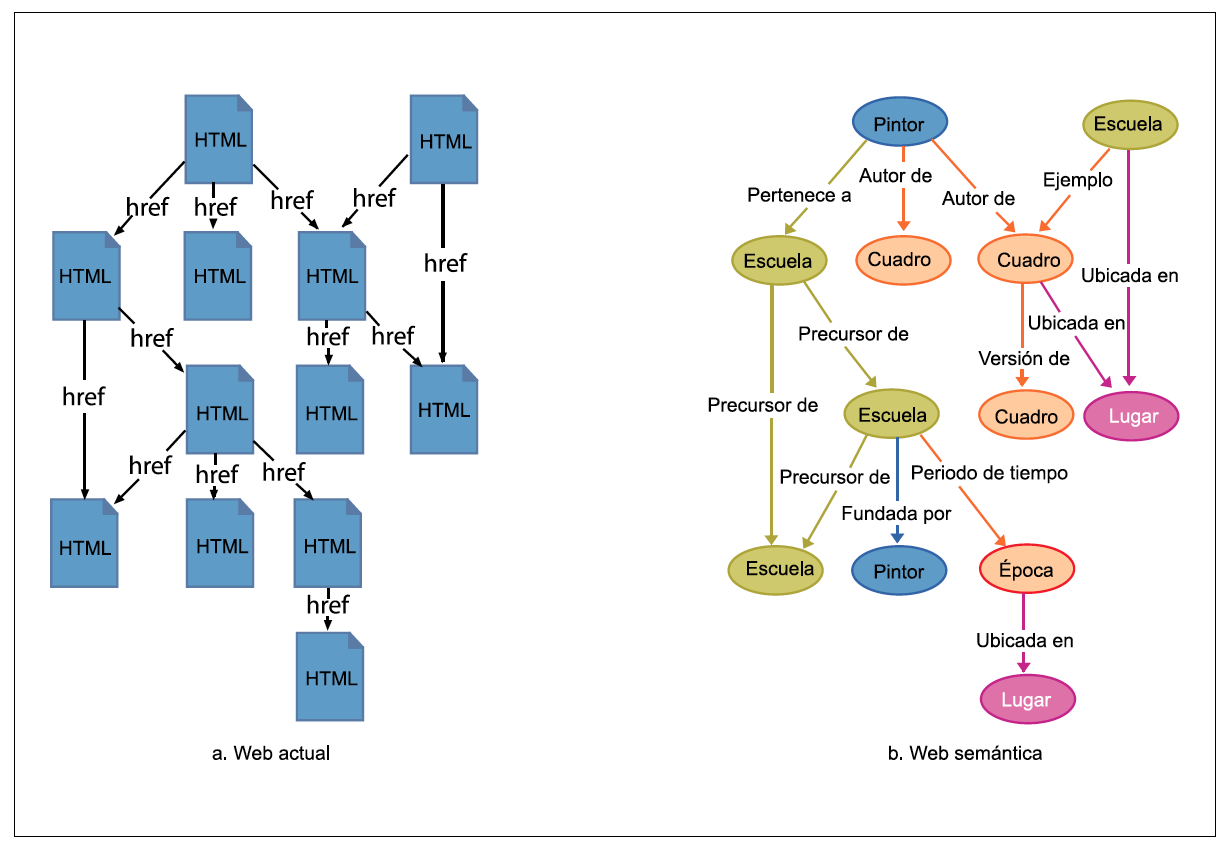
Figura 2. Web de documentos vs web de conceptos.
Perspectiva futura
El modelo de web semántica está pensado para transitar de la red actual a la de significado. Mientras que actualmente internet es una red plana, que relaciona indiscriminadamente a sitios y páginas de internet; con el nuevo modelo podemos avanzar hacia una web estructurada, donde cada página estará organizada coherentemente en función de relaciones u ontologías y contará con datos sobre los datos e información sobre la información almacenada. En pocas palabras, pasaremos de una web de documentos y palabras a una de conceptos y sus relaciones.
Teóricamente es posible y hacerla realidad requiere cambiar paulatinamente la fisonomía de la red, a partir del modelo semántico
propuesto. Hoy en día, en todo el mundo hay iniciativas desde los sectores público, privado y académico para avanzar en ese sentido. Por un lado, hace falta construir y estandarizar diferentes ontologías que den coherencia lógica a los contenidos publicados y por publicar en Internet. Por otro lado, las páginas planas tendrán que sustituirse por otras apegadas al estándar RDF y que incorporen metadatos que, a manera de fichas temáticas, clasifiquen y organicen los contenidos de Internet.
Otro esfuerzo adicional es el desarrollo de un conjunto de aplicaciones de nueva generación, aplicaciones semánticas, que exploten en todo su potencial la nueva arquitectura y funcionalidad de la plataforma semántica; es decir, los sistemas que se conectarán con otros sistemas y los entenderán gracias a ese marco común de referencia que resulta de la combinación de RDF, SPARQL y OWL.
Contribución mexicana a la web semántica
El tema de la web semántica no es nuevo en México, aunque ciertamente su difusión se concentra casi exclusivamente en universidades y centros de investigación relacionados con tecnologías de información.
Una de estas instituciones que investiga y trabaja en el desarroll de aplicaciones semánticas es Infotec, uno de los principales centros públicos de innovación y desarrollo tecnológico en el país. Infotec forma parte de la red de centros públicos del Consejo Nacional de Ciencia y Tecnología (Conacyt) y es un organismo que desde hace 10 años experimenta en el ámbito de la web semántica con resultados palpables. Su principal aportación en la materia es la plataforma de desarrollo de portales y contenidos semánticos, denominada Web- Builder, cuya cuarta y más reciente versión (SemanticWebBuilder) permite la construcción de portales de internet con incorporación de atributos semánticos: metadatos, redes semánticas y, fundamentalmente, especificaciones ontológicas dentro de los sitios.
Con esta plataforma tecnológica, Infotec lleva a cabo diferentes proyectos en el sector público que, en diferente medida, exploran las posibilidades semánticas de la web. Tal es el caso del Programa de Gobiernos Locales Digitales, mediante el cual los municipios de México tienen a su disposición una solución que los dota de un portal de gobierno electrónico y un sitio tipo “ciudad digital”, ambos preparados para funcionar con semántica dentro de sus contenidos. Otro proyecto similar tiene que ver con una oferta de solución para micro, pequeñas y medianas empresas del sector turismo. Este proyecto construirá un extenso catálogo de productos, servicios, organizaciones y demás información relacionada con el turismo, para cuyo desarrollo se ha considerado precisamente la
elaboración de una ontología apropiada al tema en cuestión.
Conclusiones
La web semántica es un concepto emergente en el ámbito de la evolución de Internet. Sin embargo, no se trata de un tema pasajero, sino de una tendencia que claramente se hará realidad paulatinamente.
Los sitios y páginas de internet, tal como los conocemos en la actualidad, tienen sus días contados. Así como sucedió en la evolución de las especies con la supervivencia del más apto, en algunos años los sitios –y en consecuencia las organizaciones de las que dependen– mejor preparados serán aquellos que puedan transmitirle a otros sistemas los significados que contienen.
Por lo que respecta a México, la existencia de iniciativas en la materia es importante, pero aún falta extender y generalizar su uso en toda la sociedad. La preocupación por transitar lo antes posible al futuro semántico debería ser una prioridad de todos: por supuesto la academia y el sector de investigación, pero también de los tres órdenes de gobierno (federal, estatal y municipal), del sector privado (grandes, medianas y pequeñas empresas) y desde luego del sector social (organizaciones civiles e individuos). No avanzaremos hacia una web estructurada si no nos organizamos antes como sociedad para lograrlo.
Referencias:
- “Guía breve de Web Semántica”, W3C oficina española.
- “Semantic Web Builder”, Infotec. http://semanticwebbuilder.org.mx
Javier Solís González es Gerente de Nuevos Productos y Servicios en Infotec. Es ingeniero en Sistemas Computacionales por el Unitec y cuenta con un posgrado en Redes Computacionales. Desde 2002, investiga y desarrolla con tecnologías semánticas, resultando en productos como SemanticWebBuilder.
Carlos O. Ramírez es Consultor en Gobierno Electrónico y Sociedad de la Información en Infotec. Estudió la Licenciatura en Ciencia Política y Administración Pública en la UNAM y ha sido editor y reportero en diferentes medios de comunicación impresos y electrónicos.
- Log in to post comments