Publicado en
En el número pasado, al hacer el análisis de los resultados del Concurso e-Quallity 2008, hacíamos referencia a la complejidad de los productos participantes.
Aunque no es el único, la complejidad es un atributo del software muy útil al distribuir adecuadamente el esfuerzo de prueba, porque ahí donde hay más complejidad hay más propensión a errores [1].
No estamos hablando de dificultad de desarrollo, que es algo más bien subjetivo que guarda dependencia con el nivel de experiencia del desarrollador, sino de un aspecto que puede ser medido de manera objetiva.
Veamos a detalle esta característica.
Las caras de la complejidad del software
Podemos hablar de dos vistas de la complejidad de un producto de software: la externa, que tiene que ver con el problema que resuelve el sistema (el proceso de negocio); y la interna, que se refiere a la manera como está programada la solución.
En la interna podemos distinguir al menos los siguientes aspectos:
- Su tamaño. Entre más grande sea un producto, mayor será su complejidad. Una métrica de tamaño (bastante primitiva, pero muy accesible y común) son las líneas de código (LCs).
- Su estructura.
Relativo a la estructura, consideremos las siguientes abstracciones de subrutinas:
Una subrutina de 10 LCs con instrucciones primitivas (v.gr. asignaciones):
(n) {
1: I1.1;
2: I1.2;
…
10: I1.10; }
Una subrutina de 7 LCs con instrucciones compuestas y primitivas:
f2 (n) {
1: I2.1;
2: if Cond2.1 then
3: I2.2;
4: else
5: while Cond2.2
6: I2.3;
7: I2.4; }
Una subrutina de 5 LCs con instrucciones compuestas y primitivas:
f3 (n) {
1: I3.1;
2: if Cond3.1 then
3: f3 (Exp3.1);
4: else
5: f3 (Exp3.2); }
Si no tomáramos en cuenta la complejidad interna, sino sólo el criterio del tamaño, diríamos que f1 es la más grande de las 3 subrutinas, pues tiene más LCs. Sin embargo, puede verse que no tiene la misma complejidad una secuencia de x instrucciones primitivas, que otra de llamadas recursivas.
Durante el análisis sintáctico, los compiladores se dan cuenta de la cantidad de instrucciones de las que consta el programa que se procesa, y verifican si la estructura de los programas siguen las reglas gramaticales del lenguaje en cuestión [2]. Sería relativamente sencillo implementar una métrica inductiva dentro de los compiladores, que durante el procesamiento de un programa asociara una complejidad a cada tipo de construcción (tanto de datos como de control) para obtener la complejidad del todo combinando las de las partes.
Del programa se puede obtener automáticamente la complejidad interna de la solución. La externa nos habla de la complejidad del problema, de la funcionalidad que se requiere del producto.
Una métrica utilizada para medir este tipo de complejidad son los puntos de función [3], que tienen la interesante ventaja de que se pueden obtener incluso a partir de los requerimientos. Una desventaja es que, si bien el algoritmo para calcularla no es complejo, no es trivial y sí es laborioso; lo peor es que obtenerla automáticamente a partir de requerimientos –cuando resultaría más útil– es prácticamente imposible a menos que éstos hayan sido especificados utilizando un lenguaje formal (como los de programación), situación casi exclusiva de los métodos formales4.
Impacto de la complejidad en la prueba de software
Como mencionamos, ahí donde la complejidad en el software es mayor, hay más propensión a errores, lo que en particular implica que debemos probar más.
Esto también podemos verlo si comparamos los grafos de control asociados a las primeras subrutinas mostradas arriba:
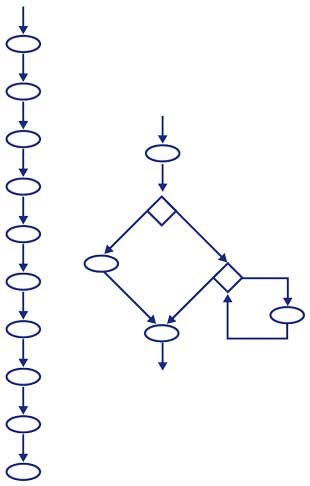
Figura 1. Izquierda: grafo de f1; derecha: grafo de f2
En el segundo grafo, la cantidad de rutas distintas necesarias para visitar todas las aristas es mayor, lo que hace crecer también la cantidad de casos de prueba que se deben diseñar y aplicar.
Algunas reflexiones
- Es muy importante tratar de mantener lo más simple posible los diseños y los programas de los sistemas que se desarrollan. Esto no solo reduce la probabilidad de introducir errores, sino que puede facilitar el mantenimiento, el reuso, y la prueba de software.
- La complejidad interna que considera la estructura de un sistema ofrece un dato más preciso que la métrica primitiva de la cantidad de líneas de código. Sin embargo, a pesar de que ese dato podría proporcionarlo fácilmente los compiladores, no es algo que suelan proveer.
- Sería muy útil obtener de manera automática la complejidad externa de un sistema (asociada a la funcionalidad) en fases tempranas del proceso de desarrollo de software (luego de especificar los requerimientos), pues ello aceleraría también el resto del proceso (comenzando con las estimaciones e incluyendo las pruebas).
Referencias
[1] León-Carrillo, L. “The Impact of Software Testing in small Settings”, en Oktaba, H. and Piatini, M. Software Processes in small Enterprises. IGI Global, 2008.
[2] Aho, A.; Lam, M.; Sethi, R.; Ullman, J. Compilers: Principles, Techniques, and Tools. Second edition.
[3] Garmus, E.; Herron, D. Function Point Analysis: Measurement Practices for Successful Software Projects. Addison-Wesley.
[4] Jean-Francois Monin, J-F. Understanding Formal Methods. Springer Verlag.
- Log in to post comments