Publicado en
Autor
En un mundo de constantes cambios a nivel de sistemas, es necesario volver a pensar acerca de los paradigmas que manejan la industria. Necesitamos ajustar nuestras herramientas a las necesidades reales que tenemos hoy en día con el fin de tener sistemas a la altura de nuestros requerimientos.
En el campo de los datos, este cambio se había detenido. Desde que en 1970 Edgar F. Codd publicó su artículo seminal sobre bases de datos relacionales, este paradigma ha dominado el panorama de los datos en los sistemas. Su longevidad es debido en gran parte a que es un modelo bien fundado en bases matemáticas que puede representarse fácilmente usando algoritmos computacionales. Gracias a esto existe una oferta amplia de sistemas de bases de datos relacionales (RDBMS), hecho que a su vez ha llevado a los desarrolladores a usarlos en prácticamente todas sus aplicaciones.
Aún así, hemos llegado a un punto en que seguir usando bases de datos relacionales para todos los casos es simplemente inviable. Existen varios problemas con los RDBMS actuales que pueden suponer una seria limitante para la construcción de aplicaciones. Estos problemas son en gran medida el motivo por el que surgió el movimiento NoSQL.
Problema 1: Leer datos es costoso
En el modelo relacional los datos se representan mediante conjuntos (tablas) relacionados entre sí. Es así que realizar una consulta por lo general involucra unir estos conjuntos (operación join) lo cual es costoso en términos de recursos de cómputo. Obviamente, hay estrategias para evitar dichos joins basadas en la desnormalización de los datos (tener pocas tablas y pocas relaciones entre ellas); pero si esa es la estrategia a seguir, ¿para qué necesitamos una base de datos relacional?
Otra opción que se ha usado para evitar el costo de lectura es utilizar un cache en memoria RAM donde se guardan los resultados de consultas comunes. Esto funciona hasta cierto punto, pero una vez que se han guardado los datos en un cache, éste se vuelve estático. No se pueden hacer consultas avanzadas sobre un cache, y no se puede interactuar con él de la misma forma con que se haría con una RDBMS. Entonces, ¿para qué eliminar el poder de un RDBMS y usar un simple cache para almacenar datos?
Problema 2: ¿Realmente necesitamos transacciones para todo?
El modelo relacional tiene escrituras de datos rápidas y eficientes. Sin embargo, si se hace uso de transacciones para preservar la integridad de los datos, habrá una penalización en el rendimiento por el uso de locks (bloqueos) a nivel de datos que decrementarán el desempeño. Lamentablemente, los RDBMS actuales por lo general hacen uso de transacciones aún si el desarrollador no las necesita.
Recuerda que el principal objetivo de las transacciones es asegurar la integridad de los datos guardados con el fin de mantener la consistencia de estos datos si se hacen consultas concurrentes. Sin embargo, no siempre es necesario este comportamiento. Piensa por ejemplo en un sistema de conteo de votos para unas elecciones. Seguramente en un sistema así, las transacciones son muy importantes ya que no se pueden presentar datos que no son consistentes. Se debe mostrar el número exacto de votos para cada candidato. En una aplicación como la descrita, es más importante la consistencia de la información que el tiempo que se tarde en inserción y consulta de los datos. Por lo que un RDBMS se ajusta muy bien a este caso. Sin embargo, piensa que además tu aplicación contendrá un sistema de conteo rápido cuya finalidad es solamente mostrar las tendencias, sin dar números exactos, en el menor tiempo posible. En estos casos, la transaccionalidad de un RDBMS sería un estorbo porque lo más importante es mostrar tendencias en tiempo real (o cercano al tiempo real). Así que si las transacciones no son importantes para nuestro modelo de negocios, ¿para qué usar un RDBMS?
Problema 3: ¿Cómo escalamos?
Los RDBMS no escalan fácilmente. Si usamos un modelo de escalamiento vertical, lo que hacemos es inflar con más recursos (CPU, RAM, espacio en disco, etc.) a nuestro servidor de bases de datos. Este tipo de escalamiento está sujeto a los límites del hardware, y su costo aumenta exponencialmente. Llegará un punto en que ya no podamos seguir escalando.
Es muy complicado escalar horizontalmente un RDBMS. El escalamiento horizontal involucra usar más servidores de forma paralela. Pero como el modelo relacional se basa en tener relaciones entre tablas, ¿cómo dividir los datos entre servidores si al final corremos el riesgo de que al hacer un join tengamos que traer los datos de varios servidores a la vez, con el costo que una operación así involucra? Para este tipo de problemas surgió la técnica sharding, del término share-nothing (compartir nada).Esto quiere decir que tendremos tablas sin relaciones con las tablas que estén en otro servidor, evitando hacer joins entre servidores. Pero si no tenemos relaciones, ¿para qué seguir usando un modelo relacional?
Problema 4: ¿Todo dominio se representa bien en un modelo relacional?
Si bien es posible representar la mayoría de modelos de dominio usando el paradigma relacional, no siempre resulta la mejor opción. En el mundo de la programación domina el paradigma orientado a objetos, lo que ya de entrada involucra el problema de traducir los objetos a un modelo relacional. Existen herramientas ORM (Object Relational Mapping) que ayudan a facilitar esta traducción. Sin embargo, como sucede en el mundo de la literatura, traducción es traición. Esto se refiere a que al final tendrás que perder algo de algún lado, o tu modelo orientado a objetos no será totalmente orientado a objetos o tu modelo relacional no será 100% ajustado a las normas de este paradigma. ¿Por qué usar un traductor objeto-relacional cuando puedes tener una base de datos que maneje objetos de forma natural? Otro tema es que el dominio de un sistema no siempre se ajustará sencillamente a un modelo relacional. Claro que podremos ajustarlo, pero es un típico ejemplo de que cuando se tiene un martillo, todo problema parece un clavo.
Un ejemplo muy relevante hoy en día de este problema son la redes sociales. En una red social tenemos muchos nodos conectados entre sí de muchas formas. Creando un grafo con millones de nodos y relaciones de diverso orden. En estos casos, una base de datos relacional no alcanza para expresar este tipo de dominios de forma eficiente ¿Por qué usar un RDBMS en un caso así, si solo te complicará más el problema?
Not Only SQL
Como respuesta a estos problemas surgió el paradigma NoSQL. NoSQL no es un sustituto a las bases de datos relacionales, es solo un movimiento que busca otras opciones para escenarios específicos como los que mencionamos, “No uses sólo SQL”. Históricamente, el término fue primero usado en los 90’s para nombrar una base de datos relacional open source. Sin embargo, como denominador de el conjunto de bases de datos alternativas al modelo relacional, fue primero usado en 2009 por Eric Evans para nombrar una serie de conferencias sobre este tipo de bases de datos. Aunque el término más correcto sería NoREL (Not Only Relational), como varios han señalado, el término NoSQL ya tiene gran aceptación. Es solo una forma de decir que no todos los problemas son clavos que pueden ser atacados con un RDBMS.
Más aún, NoSQL no es una solución única, su fortaleza está en su diversidad. El desarrollador cuenta con un abanico de soluciones y puede elegir la mejor para su problema en específico. Existen varias formas de NoSQL, que atacan los problema del escalamiento, performance y modelado de los datos de formas distintas. No hay una bala de plata, esta vez tendrás que pensar qué opción es la mejor para tu problema. Repasaremos las categorías de bases de datos NoSQL más usadas.
Almacenes Key-Value
Estas son las bases de datos más simples en cuanto su uso (la implementación puede ser muy complicada), ya que simplemente almacena valores identificados por una clave. Normalmente, el valor guardado se almacena como un arreglo de bytes (BLOB) y es todo. De esta forma el tipo de contenido no es importante para la base de datos, solo la clave y el valor que tiene asociado. La capacidad de almacenar cualquier tipo de valor se denomin schema-less, ya que a diferencia de un RDBMS no necesita definir un esquema (columnas, tipos de datos) para almacenar la información. Los almacenes key-value son muy eficientes para lecturas y escrituras, además de que pueden escalar fácilmente particionando los valores de acuerdo a su clave; por ejemplo aquellos cuya clave está entre 1 y 1000 van a un server, los de 1001 a 2000 a otro, etc. Esto los hace ideales para entornos altamente distribuidos y aplicaciones que necesitan escalar horizontalmente. Su limitante está en que no permiten realmente un modelo de datos, todo lo que guardan es un valor binario; aunque algunas implementaciones como Redis modifican este comportamiento permitiendo otro tipo de valores como Listas. Su API es bastante simple y no es más que una variación de 3 operaciones: Put, Get, Delete. Este tipo de base de datos son muy útiles para almacenar sesiones de usuario (usando su username como clave).
Recuerda que los almacenes key/ value son extremadamente rápidos pero no permiten consultas complejas más allá de buscar por su clave. Por lo que si tu aplicación necesita consultas complejas, este tipo de base de datos no se ajusta a tus necesidades.Existen implementaciones de estos almacenes solo en memoria, tales como: memcached, Oracle Coherence, JBoss Cache y WebSphere eXtreme Scale. Estas soluciones normalmente funcionan junto a un RDBMS actuando solo como un cache complementario. Además existen otras implementaciones que sí son persistentes, es decir que realmente guardan datos en filesystem y no sólo en memoria por lo que se les puede usar sin un RDBMS. Las más usadas son VMWare Redis, Amazon SimpleDB, Oracle BerkeleyDB y Tokyo Cabinet.
Bases de datos columnares
Como su nombre lo indica, guardan los datos en columnas en lugar de renglones. Por ejemplo, en una RDBMS tradicional tendríamos una tabla como la que se muestra en la figura 1, mientras que en una base orientada a columnas tendríamos las tablas que muestra la figura 2. Con este cambio ganamos mucha velocidad en lecturas, ya que si queremos consultar un número reducido de columnas, es muy rápido hacerlo. Al final tenemos una base muy parecida a las key-value. Por otro lado, este paradigma no es muy eficiente para realizar escrituras. Por ello este tipo de soluciones es usado en aplicaciones con un índice bajo de escrituras pero muchas lecturas. Típicamente en data warehouses y sistemas de Business Intelligence, donde además resultan ideales para calcular datos agregados.
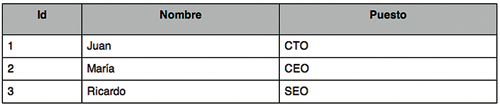
Figura 1. Estructura de datos tradicional
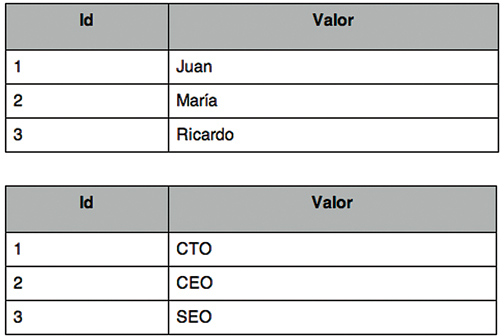
Figura 2. Estructura de datos columnar
Bases de datos orientadas a documentos
Este tipo de bases de datos son en esencia un almacen key-value con la excepción de que el valor no se guarda sólo como un campo binario, sino con un formato definido de forma tal que el servidor pueda entenderlo. Esto no quiere decir que tengan un esquema, siguen siendo schema-less, seguimos teniendo solo 2 campos y uno de ellos binario. La diferencia es que el campo binario puede ser entendido por la base de datos. Dicho formato a menudo es JSON, pero puede ser XML o cualquier otra cosa. Si el servidor entiende los datos, puede hacer operaciones con ellos. De hecho varias de las implementaciones de este tipo de bases de datos permiten consultas muy avanzadas sobre los datos, e incluso establecer relaciones entre ellos, aunque siguen sin permitir joins por cuestiones de performance. Todo esto sin perder de vista que sigue siendo un key-value con todas las ventajas que nos dan estos almacenes. Por ello este tipo de bases de datos son en gran medida los responsables del hype actual de NoSQL. Ofrecen un gran performance y escalabilidad sin perder del todo los beneficios del modelo relacional. Entre las bases de datos de este tipo, están los más famosos ejemplos de la familia NoSQL: Google BigTable, MongoDB, Apache CouchDB y Apache Cassandra. Cabe resaltar que parte del ruido que está provocando NoSQL se debe a la adopción de Cassandra (originalmente desarrollada por y para Facebook, luego donada a la fundación Apache) por parte de Twitter y Digg.
Bases de datos orientadas a grafos
Como su nombre lo indica, estas bases de datos almacenan los datos en forma de grafo. Esto permite darle importancia no solo a los datos, sino a las relaciones entre ellos. De hecho, las relaciones también pueden tener atributos y puedes hacer consultas directas a relaciones, en vez de a los nodos. Además, al estar almacenadas de esta forma, es mucho más eficiente navegar entre relaciones que en un modelo relacional. Obviamente, este tipo de bases de datos sólo son aprovechables si tu información se puede representar fácilmente como una red. Algo que ocurre mucho en redes sociales o sistemas de recomendación de productos, donde además se tiene la ventaja de poder aplicar algoritmos estadísticos para determinar recomendaciones que se basan en recorrer grafos. Entre las implementaciones más usadas está Neo4J, Hyperbase- DB e InfoGrid.
Bases de datos orientadas a objetos
Desde 1980, se ha hablado de que el remplazo natural de las RDBMS son las bases orientadas a objetos. Como su nombre lo indican, este tipo de bases se basan en el paradigma orientado a objetos y no en el modelo relacional. Por ello, a pesar de seguir basándose en tablas, tienen diferencias. Por ejemplo: pueden representar relaciones jerárquicas (generalización/ especialización), no se basan en claves primarias sino en OID (identificadores únicos de objetos calculados por la base de datos), las relaciones entre tablas son a través de punteros a objetos. Las bases orientadas a objetos nunca tuvieron el impacto esperado, pero tienen varios nichos específicos como algunas aplicaciones de carácter científico y en los últimos años aplicaciones móviles. Más aún, influenciaron positivamente al estándar SQL 1999 que incluyó algunas de sus mejoras; además de que varios vendors como Oracle y Postgres también adoptaron algunas de sus funcionalidades en sus RDBMS. Entre las bases de datos orientadas a objetos más populares están db4o, Versant y Objectivity/DB.
¿Cuál elegir?
Cómo hemos visto, cada base de datos tiene utilidades y ventajas específicas para cierto tipo de casos de uso. Las basadas en key-value son sin duda las de mejor performance pero ofrecen la funcionalidad más limitada. Las basadas en columnas son muy buenas si trabajas con datos agregados. Las basadas en documentos son una gran opción si quieres tener consultas complejas pero sin perder la velocidad de los almacenes key-value. Lo mismo con las basadas en objetos, que permiten realizar consultas muy complejas pero ofrecen poca mejora en el rendimiento. Por último no se debe de descartar a las RDBMS. De estas bases, su gran fuerte es la transaccionalidad. Si necesitas preservar la integridad de la información –y la mayoría de las aplicaciones lo necesitan–, un RDBMS sigue siendo la mejor opción.
Existe un teorema para sistemas distribuidos llamado CAP, cuyo autor es Eric Brewer. Dicho teorema explica que hay 3 requerimientos básicos en los sistemas distribuidos:
- Consistencia. Se refiere a la integridad de la información. Todos los nodos del sistema ven la misma información en todo momento.
- Disponibilidad. Que tu aplicación esté disponible siempre. Si falla algún nodo los demás pueden seguir operando sin problemas.
- Tolerancia al particionamiento. El sistema continúa funcionando a pesar de que se pierdan mensajes de forma arbitraria.
El teorema CAP establece que es imposible que un sistema satisfaga los 3 requerimientos de forma simultánea, por lo que debes elegir 2 y enfocarte en ellos. En el caso de los RDBMS, le dan más importancia a la consistencia y a la disponibilidad, en detrimento de la tolerancia al particionamiento. Por otro lado, las diferentes opciones de NoSQL dan mayor prioridad a la tolerancia y en ocasiones la disponibilidad. Así que además de revisar la funcionalidad de tu aplicación y elegir una base de datos adecuada, debes de tener en cuenta el teorema CAP para revisar cual de estos 3 elementos estás dispuesto a sacrificar para favorecer a los otros. Natahan Hurst ha publicado en su blog una guía visual que diagrama a las bases de datos contra el triángulo formado por los 3 elementos de CAP. De tal forma que sepas de antemano las debilidades y fortalezas de cada solución en el contexto del teorema CAP.
Conclusión
Las bases de datos NoSQL son ya una opción más en la cartera de alternativas para almacenar los datos de tus aplicaciones. Existen varios tipos de ellas, pero en general su objetivo principal es resolver los problemas de performance y de escalabilidad de las RDBMS. Por otro lado, las RDBMS no desaparecerán ni mucho menos. Sus capacidades transaccionales las hacen perfectas para la mayoría de las aplicaciones existentes. Sin embargo, seguramente sufrirán cambios. Así como en el pasado las bases orientadas a objetos influenciaron la evolución de las RDBMS, veremos en el futuro muchas de las ideas de las NoSQL aplicadas a las bases relacionales. En el futuro, usarás más de un solo tipo de bases de datos. Aquella que se adapte a tu aplicación y más aún, aquella que se adapte a cierto caso de uso de tu aplicación. Por lo que no será raro ver desarrollos que usen más de un solo tipo de base de datos. El punto es que debes seguir adaptándote, perderle el miedo a salir de la seguridad de un RDBMS y empezar a usar otras alternativas. Muchas de las bases de datos NoSQL tienen ya calidad de producción, algunas incluso tienen soporte comercial disponible y están respaldadas por empresas importantes. Recuerda que no se trata de usar la mejor herramienta, sino de usar la mejor herramienta para tu problema específico.
Referencias
[1] http://blog.nahurst.com/visual-guide-to-nosql-systems
Erick Camacho (@ecamacho) es Maestro en Tecnologías de la Información con especialidad en Ingeniería de Software por la Universitat Politècnica de Catalunya. Cofundador de TidySlice empresa dedicada a la formación y a la consultoría.
- Log in to post comments