Publicado en
Autor
Sin lugar a dudas, uno de los factores principales que ha coadyuvado a la adopción masiva de la tecnología es la mejora en la interacción entre los humanos y las máquinas. El objetivo es hacerlas cada día más similares a los modelos tradicionales de comunicación que se establecen entre los mismos seres humanos.
Esta “antropomorfización” (hacer que las cosas se parezcan más a los humanos) se ha hecho cada vez más patente en los paradigmas de interacción humano computadora (HCI por sus siglas en inglés). Lo que al principio eran pantallas monocromáticas de texto, donde la comunicación estaba dada por comandos crípticos que requerían conocimiento previo del entorno operativo, se ha transformado en atractivas analogías del mundo real (botones, ventanas, íconos, multimedia etc.) presentes en los modernos sistemas operativos como Microsoft Windows, MacOS o los múltiples entornos que ofrece Linux, por citar algunos.
Hasta nuestros días, sin embargo, la manera predominante en la cual podemos interactuar con una computadora, sigue siendo el teclado y el mouse. Aunque eficiente, este modelo de comunicación resulta mucho más lento que hablar de humano a humano, y para mecanografiar con velocidad razonable es necesario un entrenamiento o práctica previa.
Otros métodos, aun más “naturales” para comunicarse con computadoras, son evidentemente, la voz, la escritura a mano y el reconocimiento de gestos y figuras plasmadas en un lienzo.
Aplicaciones prácticas
El antropomorfizar cada vez más la informática, tiene como beneficio la multiplicación de escenarios en los cuales es aplicable la automatización, desde los más triviales hasta los más complejos. Esto hace que la adopción de tecnología se convierta además en un factor de ahorro y eficiencia para aquellas empresas que decidan implementarla.
Supongamos, por ejemplo un sistema automatizado que se encargue de vender boletos de cine, con una interacción completamente natural. A este sistema le denominaremos CinemaNET. La interacción entre el humano y la maquina en este pretendido sistema, sería a través de comandos de voz. El sistema solicitaría información al usuario a través del habla humana (es decir, el sistema hablaría con el usuario) y recibiría la información del usuario con la voz del mismo.
Actualmente esto es completamente factible usando la plataforma .NET 4.0 y Windows 7. Microsoft tiene una larga historia en la investigación de tecnología enfocada a métodos alternativos de interacción humana. Actualmente ofrece una solución “server-side” llamada Speech Server, que es parte de Office Communications Server y brinda una plataforma para la creación e instalación de aplicaciones basadas en voz en ambientes corporativos. Windows 7 también incluye tecnología de reconocimiento y síntesis de voz, análisis de texto y el engine de conversión texto-voz Microsoft SAM. Muchas de las APIs de estas tecnologías son nativas del sistema operativo u componentes COM, por lo que es posible acceder a ellas mediante C++ y/o programación no administrada. Sin embargo, el .NET Framework a partir de su versión 3.0, y con mejoras sustantivas en NET 4.0, facilita enormemente al desarrollador el consumo de estos servicios del sistema operativo, haciendo que la integración de diferentes tecnologías de interacción alternativa sean tareas verdaderamente sencillas como veremos a continuación.
Text to Speech
La síntesis de habla es la reproducción computarizada de voz e idioma humanos. Es un problema que dista de ser trivial, debido a la variedad de excepciones a las reglas de pronunciación. Algunos idiomas como el español o el italiano, tienen ortografías fonéticas, es decir, que una grafía o letra representa un único sonido y su reproducción es razonablemente sencilla derivado de esto. (Una “a” siempre suena “a”). Sin embargo otros idiomas, como el alemán, mezclan la ortografía fonética con varias excepciones donde las combinaciones de vocales o de posición de diversas letras, o inclusive el orden de las palabras, modifican el sonido final —por ejemplo, en alemán el diptongo “ei” suena “ai”. Y existen otras lenguas, como el inglés cuya ortografía es completamente defectiva —por ejemplo la “e” inglesa puede sonar como “i” en “be”, como “e” en “bet” o no sonar como en “make”—. Incluso en idiomas tonales —como el chino—, el mismo sonido puede significar algo distinto de acuerdo al tono con el que se exprese. A todo esto hay que añadir, entre muchos otros retos las palabras que representan preguntas, exclamaciones y el acento de cada hablante.
Por todo esto, no es posible hacer un solo sintetizador, sino que se debe hacer uno por cada idioma, y la complejidad para generarlos es bastante alta. Históricamente, los sistemas operativos Windows han incluido sintetizadores de texto como Microsoft SAM, pero además hay sintetizadores de terceros que prácticamente hablan cualquier idioma y acento necesario. Estos sintetizadores son accesibles a través del .NET Framework de una forma bastante simple.
Retomando el ejemplo de CinemaNet, supongamos que el programa muestra una pantalla y recibe al usuario con una cálida bienvenida.
El código del listado 1 muestra cómo utilizar la capacidad text to speech con el .NET Framework 4.0. Primero inicializa el sintetizador de voz y lee el texto dentro del método Speak() del objeto SpeechSynthesizer, donde se encapsula toda la funcionalidad de síntesis texto a voz. Como mencioné anteriormente, Windows Vista y Windows 7 incluyen por defecto el motor de síntesis Microsoft SAM, que es capaz de leer texto en inglés. Para este ejemplo estoy haciendo uso de un motor de síntesis de terceros (Cepstral Marta) que soporta síntesis en español.
using System.Speech;
using System.Speech.Synthesis;public void Hablar()
{
// Inicializo el objeto y selecciono un engine de sintesis de 3os en español:
// “Cepstral Marta”
SpeechSynthesizer Sintetizador = new SpeechSynthesizer();
Sintetizador.Volume = 100;
Sintetizador.SelectVoice(“Cepstral Marta”);
Sintetizador.Speak(“Bienvenidos al expendedor de cinetickets automatizado”);
Sintetizador.Speak(“Por favor dígame la película que desea ver”);
}Listado 1. Text to speech en .NET 4.0.
Reconocimiento de voz
Siguiendo con el ejemplo de CinemaNET, el usuario está a punto de dictarle al sistema la película que ha elegido mediante reconocimiento de voz.
Para lograr este objetivo es necesario el proceso de speech recognition, que se define como la conversión del habla humana a texto. En un sistema informático como CinemaNET, el concepto se extiende a las gramáticas, que son un conjunto de comandos predeterminados basados en la voz humana que realizan acciones específicas dentro de un sistema computacional.
El listado 2 muestra un código básico para reconocer la voz de un hablante.
using System.Speech;
using System.Speech.Recognition;
public void Escuchar()
{
// Inicializa el motor de reconocimiento
SpeechRecognitionEngine Reconocedor = new SpeechRecognitionEngine();
Reconocedor.UnloadAllGrammars();
// Agrego una gramática con las opciones que espero recibir
Choices Comandos = new Choices(new string[]
{
“Shrek”, “Encuentro explosivo”, “Caín”, “Eclipse”,
”Fuego”, ”Una pareja dispareja”
});
Reconocedor.LoadGrammar(new Grammar(new GrammarBuilder(Comandos)));
// Inicia la escucha con el dispositivo de entrada de audio predeterminado
Reconocedor.SetInputToDefaultAudioDevice();
Reconocedor.RecognizeAsync();
//Si se reconoce alguna palabra dentro de la gramática,
// muestra el resultado y el índice de confianza del reconocimiento
Reconocedor.SpeechRecognized +=
(object sender, SpeechRecognizedEventArgs e) =>
{
MessageBox.Show(e.Result.Text + “ “ + e.Result.Confidence.ToString());
Reconocedor.RecognizeAsync();
};
// Si no encuentra coincidencias
Reconocedor.SpeechRecognitionRejected +=
(object sender, SpeechRecognitionRejectedEventArgs e) =>
{
MessageBox.Show(“No pude reconocer la película que me dijiste. Intenta de nuevo”);
Reconocedor.RecognizeAsync();
};
}Listado 2. Reconocimiento de comandos por voz.
En este código podemos ver la inicialización del objeto SpeechRecognitionEngine, donde reside la funcionalidad de reconocimiento de voz en .NET. Posteriormente hacemos el uso de la función LoadGrammar que recibe el objeto Grammar, que a su vez contiene los comandos que el programa está dispuesto a esperar. En el ejemplo se muestra una carga directamente con un objeto Choice inicializado con un arreglo de cadenas, sin embargo, también es posible utilizar el estándar del W3C Speech Recognition Grammar Specification (SRGS) http://www.w3.org/TR/speech-grammar para el caso de que existan gramáticas cambiantes, y para efectos de aumentar la compatibilidad entre plataformas.
En el ejemplo, el programa reconocerá única y exclusivamente los comandos especificados en el objeto Choice: “Shrek”, “Encuentro explosivo”, “Caín”, “Eclipse”,”Fuego”,”Una pareja dispareja”. En el caso de que el reconocimiento sea exitoso, se dispara el evento SpeechRecognized y se mostrará la opción elegida, así como el grado de confianza del reconocimiento.
Si no se reconoce, es decir, si se dice algo que no se encuentre dentro de las opciones especificadas, se levanta el evento SpeechRecognitionRejected y se muestra un mensaje al usuario.
Otra aplicación es el dictado, es decir donde no existen opciones y se espera recibir cualquier palabra. Para recibir dictado se hace uso de DictationGrammar. El listado 3 muestra nuestro código para recibir dictado.
using System.Speech;
using System.Speech.Recognition;
public void EscucharDictado()
{
SpeechRecognitionEngine Reconocedor = new SpeechRecognitionEngine();
Reconocedor.UnloadAllGrammars();
// Agrego una gramática del tipo dictado para recibir cualquier palabra
Reconocedor.LoadGrammar(new DictationGrammar());
Reconocedor.SetInputToDefaultAudioDevice();
Reconocedor.RecognizeAsync();
//Si se reconoce alguna palabra dentro del dictado
// muestra el resultado y el índice de confianza del reconocimiento
Reconocedor.SpeechRecognized +=
(object sender, SpeechRecognizedEventArgs e) =>
{
MessageBox.Show(e.Result.Text + “ “ + e.Result.Confidence.ToString());
Reconocedor.RecognizeAsync();
};
}Listado 3. Capacidad de Dictado.
En Windows Vista y Windows 7, se incluye la capacidad automática de cambio de idioma del sistema operativo mediante los Language Packs. Estos paquetes incluyen también el motor de reconocimiento de voz , por lo que es posible escuchar prácticamente cualquier idioma. El sistema de reconocimiento de voz interpreta por default el dictado de acuerdo al idioma en el que se encuentre el sistema operativo.
Multitouch
Con el uso en aumento de dispositivos portátiles con capacidades de Multitouch como Tablet PC, iPads o la constante aparición de quioscos digitales bancarios o de centros comerciales, entre otros, las necesidades desde el punto de vista del desarrollador y diseñador gráfico para poder explotar estas plataformas, también ha ido en aumento.
En la plataforma .NET , Windows Presentation Foundation 4.0 contiene una serie de objetos que representan las manipulaciones que el usuario realiza durante su interacción con una pantalla de touch.
Supongamos que nuestro CinemaNET muestra los carteles con el arte gráfico de las películas, o bien video o escenas de la película en una pantalla multitouch. Para lograr esto, basta agregar un objeto Canvas (o cualquier otro objeto contenedor) a una ventana de XAML y llenarlo con todas las imágenes de un directorio, habilitando la propiedad IsManipulationEnabled de las mismas, que es la que permite recibir manipulaciones desde una pantalla touch (también pueden ser videos, paths o cualquier elemento que herede de UIElement, y el resultado es el mismo). Este código se puede apreciar en el listado 4.
public static void AgregarImagenesACanvas(Canvas canvas)
{
DirectoryInfo objdi = new DirectoryInfo(@”C:\CinemaNET\galeria\”);
FileInfo[] objArchivos = objdi.GetFiles(“*.jpg”);
objArchivos.ToList().ForEach(o =>
{
Image Imagen = new Image();
Uri src = new Uri(o.FullName, UriKind.Absolute);
BitmapImage img = new BitmapImage(src);
Imagen.Source = img;
//Esta propiedad habilita el multitouch de cualquier objeto
// que herede de UIElement en WPF
Imagen.IsManipulationEnabled = true;
//Se agrega la imagen dinámicamente al objeto contenedor
canvas.Children.Add(Imagen);
});
}Listado 4. Agregando imágenes a un objeto del tipo Canvas.
Posteriormente, es necesario crear una suscripción al evento ManipulationDelta, y en su manejador utilizamos un objeto del tipo MatrixTransform que representa una transformación arbitraria de tamaño, posición y perspectiva dentro de WPF. La información de esta transformación viene contenida en el objeto ManipulationDeltaEventArgs de la firma para la función manejadora del evento como se muestra en el listado 5.
void ManipularObjeto(object sender, ManipulationDeltaEventArgs e)
{
var element = e.Source as FrameworkElement;
var deltaManipulation = e.DeltaManipulation;
//Se crea un objeto MatrixTransform con la información de la manipulación
var matrix = ((MatrixTransform)element.RenderTransform).Matrix;
//Se obtiene la posición central del elemebto a manipular
Point center = new Point(element.ActualWidth / 2, element.ActualHeight / 2);
//Se establecen los parámetros de la transformación
center = matrix.Transform(center);
matrix.ScaleAt(deltaManipulation.Scale.X, deltaManipulation.Scale.Y, center.X, center.Y);
matrix.RotateAt(e.DeltaManipulation.Rotation, center.X, center.Y);
matrix.Translate(e.DeltaManipulation.Translation.X, e.DeltaManipulation.Translation.Y);
//Se aplica la transformación
element.RenderTransform = new MatrixTransform(matrix);
e.Handled = true;
}Listado 5. Código básico para manipulación con multitouch.
La figura 1 muestra la imagen al ejecutar el programa y realizar la manipulación.
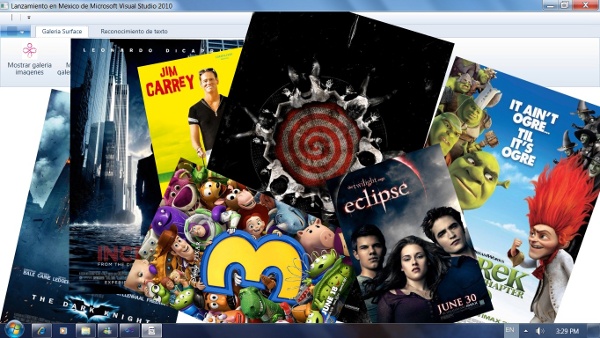
Figura 1. Manipulación Multitouch.
Cabe señalar que el API de WPF es compatible para programar Microsoft Surface.
Reconocimiento de escritura a mano (tinta digital)
Cerraremos este artículo mostrando las capacidades que tiene la plataforma .NET para el reconocimiento de la escritura a mano, es decir la capacidad para recibir e interpretar los trazos de un humano sobre una superficie, como si se escribiera con una pluma o lápiz tradicional, y su posterior análisis para representar y almacenar esta información como texto digital (ASCII, UTF, Unicode etc.).
Supongamos que CinemaNET, además de proporcionar la interface por voz que hemos visto anteriormente, también tenga la capacidad de reconocer el texto que un usuario escribe dentro de su pantalla touch. Para lograrlo, podemos hacer uso del objeto InkCanvas que permite a un usuario dibujar con un stylus ( o con su dedo) trazos. Estos trazos pueden ser analizados por el objeto InkAnalyzer, que además de reconocer texto, permite determinar, si un objeto es (o tiene forma) de alguna primitiva geométrica (círculos, rectángulos, rombos, polígonos etc.). El ensamblado que contiene el analizador de tinta (InkAnalyzer) se encuentra disponible con el SDK de Windows 7 o Windows Vista.
Primero añadimos a nuestra ventana de WPF un objeto del tipo InkCanvas, que equivale a un código como el siguiente:
<InkCanvas StrokeCollected="OnStrokeCollected" />
Posteriormente manejamos el evento StrokeCollected y mandamos a analizar lo que pinte el usuario. Esto se aprecia en el listado 6.
private void onStrokeCollected(object sender, InkCanvasStrokeCollectedEventArgs e)
{
InkAnalyzer AnalizadorTinta = new InkAnalyzer();
AnalizadorTinta.AddStroke(e.Stroke);
//El 2058 representa el idioma español
AnalizadorTinta.SetStrokeLanguageId(e.Stroke, 2058);
//Se manda a ejecutar el análisis
AnalizadorTinta.BackgroundAnalyze();
//Se verifica si se detectó una palabra y se muestra en la pantalla
AnalizadorTinta.ResultsUpdated +=
(object sender2, ResultsUpdatedEventArgs e2)=>
{
if (e2.Status.Successful)
{
ContextNodeCollection nodes = ((InkAnalyzer)sender2).FindLeafNodes();
foreach (ContextNode node in nodes)
{
if (node is InkWordNode) //si detecta una palabra
{
InkWordNode t = node as InkWordNode;
MessageBox.Show( t.GetRecognizedString());
}
}
}
};
}Listado 6. Reconocimiento de escritura a mano
La figura 2 ilustra el resultado.
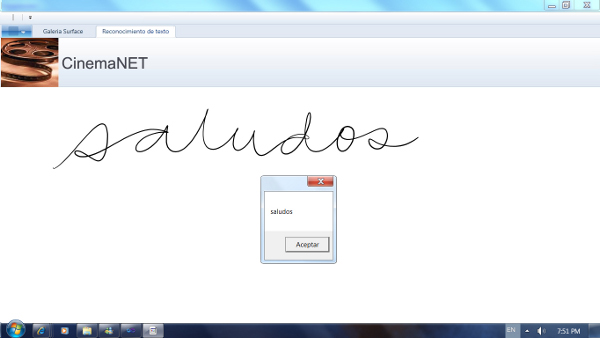
Figura 2. Reconocimimento de escritura.
Conclusión
El .NET 4.0 Framework proporciona todo lo necesario para construir aplicaciones con dispositivos de entrada alternativos al teclado y al mouse de una manera sencilla y eficiente sin necesidad de tener que programar directamente con la API del sistema operativo, proporcionando así opciones ilimitadas para aumentar la usabilidad de nuestras aplicaciones, haciendolas más atractivas y aumentando su aplicación en una gran cantidad de escenarios.
El código fuente de los ejemplos mostrados en este artículo está disponible en http://miguelangelmoran.com
Miguel Angel Morán (@SrBichi) es un Microsoft Most Valuable Professional (MVP) en C#. Cuenta con 13 años de experiencia desarrollando y lidereando soluciones de software de misión crítica en las más diversas industrias. Participa activamente en conferencias, cursos, comunidades de desarrollo y divulgación en TI. Colabora en emLink como consultor e imparte cursos de actualización tecnológica.
- Log in to post comments