Publicado en
El Cliente dice: “¡Te damos tiempos límite razonables! ¿Por qué no puedes cumplirlos?”
Ese argumento es muy común en el desarrollo de software y el hecho de fijar la fecha de entrega antes de establecer los requisitos, es el problema más antiguo de la ingeniería de software, pero si ya estamos conscientes de todo esto ¿por qué la improvisación parece ser el estándar? y ¿por qué no se tienen procesos de estimación bien definidos?
Hoy en día existen diversas herramientas y metodologías que nos permiten estimar costos como SPR KnowledgePlan de Capers Jones o COCOMO II de Barry Boehm, por comentar algunos. Sin embargo fenómenos como el “Proyecto interminable” y la “Marcha de la muerte” siguen siendo comunes en muchos desarrollos. Existen muchos factores que afectan las estimaciones de costo como:
- Incertidumbre en los requerimientos.
- Términos contractuales rígidos.
- Salud financiera (ganar licitaciones sacrificando costo y tiempo).
- Falta de experiencia con “X” tecnología.
No existe una forma simple de calcular el esfuerzo requerido para desarrollar un proyecto de software. Las estimaciones iniciales se hacen bajo la base a la definición de requisitos que el cliente provee a un alto nivel (funcionalidades o pantallas). Los pasos típicos en una estimación son:
- Análisis de los requisitos.
- Predicción del tamaño.
- Descripción de las Actividades.
- Estimación de fallas potenciales y métodos de eliminación de defectos en el software.
- Estimación de requisitos del personal.
- Ajuste de suposiciones basadas en capacidades y experiencia.
- Estimación del esfuerzo y fechas límite.
- Estimación de costos del desarrollo.
- Estimación de costos de mantenimiento y mejora.
A medida de que los proyectos de software aumentan en complejidad, se observa que no existe una relación simple entre el precio de software al cliente y los costos involucrados en el desarrollo, así como la falsa creencia que hay una relación entre el número de desarrolladores contra el número de funcionalidades del proyecto. Por eso y para facilitar el proceso de estimación se han establecido a lo largo del tiempo, métricas que ayudan a dar una idea aproximada del tamaño del software:
Medidas relacionadas con el tamaño del código ( LOC - Lines of code). Esta forma de medir el tamaño de un software era utilizado cuando los lenguajes de programación, patrones de desarrollo y entornos de desarrollo (IDE), no estaban ampliamente desarrollados. Hoy en día es impráctico tratar de estimar el software a través de sus líneas de código ya que depende de la experiencia de los programadores o si hablamos de lenguajes de programación dinámicos como Ruby, Scala y Groovy o herramientas e IDEs que facilitan gran parte del trabajo de programación.
Medidas relacionadas con la función (UFC – Puntos de Función). El total de puntos de función no es una característica simple sino que es una combinación de características del software a las cuales se les asigna un valor que cambia dependiendo de su complejidad.UFC es igual a la suma de los “n” elementos evaluados por el peso asignado al tipo de función.
Sin embargo a lo largo del proyecto las funciones cambian, las métricas de puntos de función tienen en cuenta esto y multiplican los UFC iniciales por un factor de complejidad (asignándoles un factor de peso que va desde 3 a 15 puntos). Una desventaja de los puntos de función se presenta cuando el sistema está orientado por eventos. Por eso algunos autores piensan que UFC no es muy útil para medir productividad.
Los Puntos de Objeto (PO). Los PO se utilizan en el modelo de estimación Cocomo II con el nombre de Puntos de Aplicación. Estos son una alternativa a los UFC, y son usados en los lenguajes orientados a objetos y de scripts. Dan valor a cada pantalla dependiendo de su complejidad: simples = 1, medianamente complejas = 2, muy complejas = 3. Los reportes van de 2 a 8 dependiendo del nivel de complejidad, y los módulos en lenguaje imperativo como Java o C++ se contabilizan como 10. Esto puede ser relacionado directamente a las historias de usuario de algunas metodologías agiles con lo cual facilita la estimación de la iteración.
Modelo Constructivo de Costo: COCOMO II
Uno de los modelos de estimación más usados es COCOMO (Constructive Cost Model) creado por el Dr. Barry Boehm. COCOMO apareció por primera vez en su libro Software Engineering Economics [1] en 1981. En 1999 se definió la segunda versión del modelo que toma en cuenta el proyecto, el producto, el hardware y la experiencia del equipo de desarrollo en sus fórmulas de estimación de costo, incluyendo mecanismos de predicción de tiempo.
Cocomo II provee niveles que nos permiten hacer estimaciones en diferentes momentos del desarrollo ya que la estimación de costos debe de ser un proceso dinámico a lo largo del desarrollo, actualizando constantemente las variables, la evolución del equipo de desarrollo, las herramientas y lenguajes involucrados. Los distintos niveles son:
Construcción de prototipos. Las estimaciones de tamaño están basadas en puntos de aplicación con base en componentes reutilizables, prototipos y la fórmula para estimar el esfuerzo requerido es muy simple: tamaño / productividad.
Diseño inicial. Está basado en los requerimientos originales del sistema a un alto nivel (pantallas, reportes, procesos, transacciones) lo que son traducidos a puntos de aplicación, esto nos sirve para hacer una predicción temprana del costo.
Reutilización. Este nivel se utiliza para calcular el esfuerzo requerido para integrar el código generado por los IDE’s o herramientas de generación de código reutilizable como Spring Roo o Genexus por ejemplo, tomando en cuenta componentes reutilizables que facilitan el desarrollo como Apache Commons.
Post-arquitectura. Ya diseñado el sistema se pueden hacer estimaciones más precisas del tamaño del software, aquí es importante señalar que el software tiene una tasa de crecimiento de los requerimientos del sistema entre el 2 y el 5 por ciento mensual, por lo cual no es posible hacer una estimación exacta pero las predicciones de costo se pueden acercar mucho a la realidad gracias a la aplicación de métricas que nos permiten tener una variación muy pequeña con respecto al producto final.
Cocomo está basado en fórmulas para hacer las estimaciones, véase la figura 1 donde se estima el esfuerzo del personal por mes (PM), después se hace la estimación del tamaño del proyecto (SIZE) y finalmente se obtiene una proyección del esfuerzo requerido (B) contemplando los factores involucrados (SF).
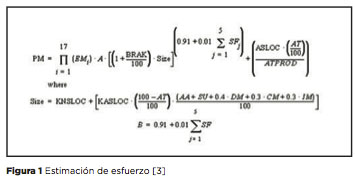
Obviamente el realizar los cálculos manualmente es una tarea lenta y tediosa por lo cual existen muchas aplicaciones que se encargan de realizar todas las fórmulas, como USC COCOMO II que es la aplicación de la página oficial de COCOMO. Podemos descargar gratuitamente el software en http://swgu.ru/sg3414
Conclusión
La estimación de costos es una actividad muy importante en el desarrollo de software. Esta actividad no es estática sino que cambia en diferentes puntos del ciclo de vida del desarrollo.
Se tienen que hacer estimaciones desde diferentes puntos de vista, desde la predicción de costos hasta la retrospectiva de comportamiento del costo, para lo cual las herramientas de estimación nos ayudan a agilizar la tarea. Sin duda el poder hacer predicciones con respecto al costo del software nos da ventajas que facilitan el éxito de un proyecto, sin embargo esto no debe de ser exhaustivo ya que se tienen variables que el modelo no contempla totalmente como la incertidumbre, la complejidad o factores humanos de los cuales no se puede tener control, por lo cual se deben tomar en cuenta los riesgos del proceso de desarrollo de software.
Una de las ventajas de COCOMO es el poder medir el comportamiento de costo de un proyecto de software de forma interna para la empresa de desarrollo. Lo que nos permite tener un referente en diferentes puntos del proyecto y así poder comprobar que las proyecciones de costo originales se cumplan.
Referencias
[1] B. Boehm. “Software Engineering Economics”. Prentice Hall, 1981.
[2] C. Jones. “Estimating Software Costs”. McGraw-Hill, 2007.
[3] “COCOMO II Model Definition Manual”. Center for Software Engineering, USC.
[4] B. Boehm, C. Abts, et al. “Software Cost Estimation with COCOMO II”. Prentice Hall, 2000.
Héctor Cuesta-Arvizu es Lic. en Informática y actualmente cursa la maestría en ciencias de la computación en la UAEM Texcoco. Cuenta con seis años de experiencia desarrollando y administrando proyectos de software en el ámbito de manufactura y recursos humanos. Adicionalmente se desempeña como instructor de TI para Nyce en el área de base de datos e ingeniería de software. @hmcuesta
M. en C. José Sergio Ruíz Castilla es Profesor Investigador de la Universidad Autónoma del Estado de México, estudia el Doctorado en Ingeniería de Software y trabaja en proyectos de Ingeniería de Software y Sistemas de Gestión del Conocimiento.
- Log in to post comments