Publicado en
Autor
La generación de contenidos masivos de información dentro de Internet, ha generado nuevos paradigmas de respuesta al almacenamiento de información. Los manejadores tradicionales de administración de bases de datos relacionales (RMDBS) han tenido dificultad para enfrentar los nuevos esquemas de almacenamiento y manejo intensivo de información que las nuevas aplicaciones y ambientes requieren. Paradigmas nuevos surgen y permiten expandir el panorama de almacenamiento de datos en esquemas poco convencionales, los cuales revisaremos de manera general en este documento.
¿Qué es NOSQL?
Nueva generación de bases de datos que puede cubrir cualquiera de estos puntos: ser no relacional, distribuida, opensource y escalable de manera horizontal. La idea original fue bases de datos web escalables modernas.
Generalmente otras características aplican como: libre de esquema, soporte sencillo de replicación, API sencilla, eventualmente consistente, una gran cantidad de datos y más.
Entonces el término “nosql” (la comunidad ahora lo traduce como “no solo sql”) debe ser visto como un alias.
Arquitecturas
Llave/Valor.
La arquitectura Llave/Valor consta en una llave como “Colonia” que se asocia con un valor “Centro”. Estas estructuras pueden ser utilizadas como colecciones, diccionarios, arreglos asociados o caches. Los valores almacenados pueden ser textos largos no solo enteros o cadenas cortas, lo cual los hace ideales para guardar comentarios, mensajes o descripciones largas. Cada llave almacenará un conjunto de contenedores (campos o columnas), cada contenedor corresponde a un nombre y un valor. Se genera un contenedor por cada pedazo de dato que se tenga. Cada registro tiene una llave y una colección de valores.
Las búsquedas realizadas en este tipo de estructuras son rápidas ya que funcionan bajo el concepto de tablas hash. Estas búsquedas también son sencillas de administrar a lo largo de la base de datos, lo que permite barrer clusters de servidores sin dificultad. Las bases de datos Llave/Valor están diseñadas para escalarse de manera horizontal y para que sean veloces.
Estas estructuras resuelven situaciones en donde la información no está relacionada. Pueden utilizarse para llevar el registro de la actividad de los usuarios en un sitio Web.
Considerando la ausencia de índices, este tipo de estructuras no son útiles para realizar operaciones complejas con los datos, solo soportan sentencias simples de creación, lectura, actualización y eliminación.
Arquitectura de documentos
La arquitectura basada en documentos utiliza una estructura compleja de datos denominada documento para almacenar los campos de cada registro. Se pueden generar arreglos de registros o anidamientos de documentos. Estas estructuras de datos son del tipo JavaScript Object Notation (JSON), XML o BSON o del tipo binario como PDF (ver figura 1). Estos documentos pueden ser invocados utilizando una URL. En conjunto con Javasript y HTML se pueden invocar a los documentos teniendo la capacidad de generar un sitio web completo a partir de ellos. Esta facilidad de interactuar por medio de una URL utilizando el protocolo http distingue a las bases de datos de documentos de las bases de datos de Llave/valor.
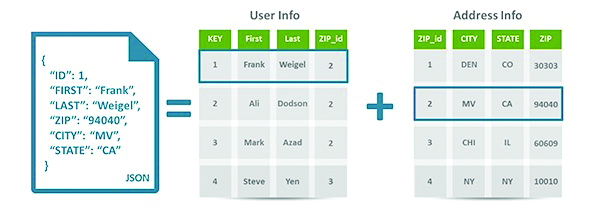
Figura 1. Documento JSON utilizado en CouchDB para representar la información del usuario y su dirección.
La distribución de documentos entre varios servidores es simple y su replicación a través de una implementación distribuida es sencilla de implementar. La utilización de estas bases de datos en ambientes en donde la información no está definida y se desconoce el volumen a manejar, facilita el uso de documentos como elementos de información para crear objetos que se adapten con los lenguajes actuales de programación. Se debe considerar que los queries que manejan grandes joins, no pueden ser ejecutados en este tipo de bases aun cuando se manejan índices en la administración de los registros. La existencia de documentos con información redundante o incompleta es común en este tipo de bases, por lo que la desnormalización de la información no debe ser extraño al estar operando la base de datos.
Columnar
El modelo de columnar utiliza el esquema de llave/valor para almacenar la información pero introduce un patrón de jerarquías y un semi-esquema para ordenar y almacena los datos, generando las columnas por la que es llamada esta arquitectura. Las filas contenidas en esta base de datos pueden variar, es decir pueden contener un número diferente de campos ya que es una propiedad de los registros llave/valor. Las tablas de estas bases de datos deben ser declaradas, lo cual amarra a este tipo de bases a la presencia de esquemas definidos para trabajar los datos. Ver Figura 2.

Figura 2. Esquema de tabla en HBase con filas, llaves, familias de columnas, columnas y valores.
Estas bases de datos se escalan de manera horizontal, están pensadas para solucionar problemas de Big Data. Cuentan con la facilidad de versionar y comprimir su contenido.
Esta capacidad de versionado facilita el manejo de sitios web dentro de la base de datos, tanto para que sean almacenados como para que sean controlados. La historia de los cambios en un sitio son almacenados de manera automática en la base de datos. La capacidad de almacenamiento de la base de datos está en el orden de los gigabytes o terabytes, ya que la base puede almacenarse en distintos servidores y la utilería de replicación puede reaccionar ante fallos en el almacenamiento de los datos. Se debe conocer por adelantado la forma en que se va a manejar el esquema de datos, ya que debe pensarse en resolver de manera fácil las diferentes consultas (queries) que se le van a presentar, no importando el contenido de la base.
La terminología de la base de datos es muy similar a las bases de datos relacionales. No se cuentan con índices para localizar u ordenar la información, solo se cuenta con las filas llave que definen el orden de los registros, no se puede ordenar la base ni por columnas ni por valores.
Grafos
Las bases de datos de grafos reconocen entidades en un negocio o dominio, y explícitamente siguen las relaciones entre estas. Las entidades reciben el nombre de nodos y las relaciones el nombre de aristas. Nuevas aristas pueden ser agregadas en cualquier momento, permitiendo relaciones uno a muchos o muchos a muchos de una manera sencilla, evitando el uso de tablas intermedias para la representación de esta unión, como será en el caso en una base de datos relacional. Estas bases de datos se enfocan más en las relaciones de los datos, más que en las características de sus valores.
Estas bases de datos son ideales para el manejo de información no estructurada, aún mejor que las bases de datos orientadas a documentos. Se puede utilizar este tipo de base de datos para guardar información relacionada entre si y puede ser representada a partir de estructuras compuestas de nodos y aristas que conforman un grafo. Este grafo puede ser barrido ubicando la relación existente entre sus nodos. Una red social pudiera ser almacenada dentro de esta base de datos en donde los usuarios representan nodos que guardan cierta relación con sus nodos vecinos. Los sistemas orientados a objetos serán bien almacenados en estas bases, dada la similitud del objeto con un nodo dentro de la base. Se debe tener en cuenta que debido a la complejidad que pueden alcanzar los nodos no es recomendable particionar este tipo de estructuras ya que los brincos entre nodos de red no son resueltos de manera rápida por la base de datos.
Es común que si se utiliza esta base de datos, forme parte de un “ecosistema” de bases de datos en donde el volumen de información se almacena en otras bases y la base de grafo almacena las relaciones entre los datos.
Entonces, base de datos NoSql debe entenderse como: la herramienta de almacenamiento de información que derivado de grandes volúmenes de información y una necesidad creciente de disponer la información de manera inmediata, no se apega a las características principales de un manejador RMDBS, algunas bases no cuentan con esquemas de datos definidos, otras tantas permiten el almacenamiento de su información en servidores distribuidos por el mundo, algunas dejaron de utilizar el SQL como lenguaje para manipulación de datos, otras manejan la replicación de datos y el manejo de errores de manera natural sin necesidad de configuraciones de hardware costosas.
Referencias
- http://www.nosql-database.org/
- http://nosql.mypopescu.com/
- http://www.techrepublic.com/blog/10-things/10-things-you-should-know-about-nosql-databases/
Ismael Villegas es docente de a nivel Maestría y Licenciatura, consultor de sistemas en el manejo de desarrollos de software y administración de proyectos tecnológicos en el ramo de instituciones financieras por 16 años. Actualmente trabajando en un proyecto global en la migración de plataformas tecnológicas del cliente en México, hacia ambientes virtualizados concentrados en Estados Unidos. Recientemente certificado como Project Manager Profesional(PMP) por el Project Management Institute(PMI).
- Log in to post comments