Publicado en
En el número anterior mostramos la Jerarquía de lenguajes de Chomsky, que se construye considerando la complejidad de la estructura de las reglas del conjunto R que define cada tipo de lenguaje. Partamos ahora no de las gramáticas, sino de los lenguajes, y apliquemos unas extensiones: llamamos…
Lenguajes Regulares(o de Tipo 3, o de manera corta Lgs3) a aquellos que pueden definirse utilizando Gramáticas Regulares, cuyasreglas son de la forma A→ B d | d (o menos compleja).
(Nota: las reglas podrían ser de la forma A→ d B | d , pero no se pueden mezclar ambas formas en una misma gramática.)
Lenguajes Libres de Contexto (o Tipo 2, o Lgs2) a aquellos que pueden definirse utilizando Gramáticas Libres de Contexto, cuyasreglas son de la forma A→ α (o menos compleja).
Dentro de estos lenguajes existen varias divisiones. Una de las más relevantes es la que diferencia entre los lenguajes determinísticos y los no-determinísticos; un ejemplo de estos últimos es an bn ∪ an b2n , que como podrán intuir, para procesarlo es necesario que el compilador asociado realice backtracking.
Lenguajes Sensibles al Contexto (o Tipo 1, o Lgs1) a aquellos que pueden definirse utilizando Gramáticas Sensibles al Contexto, cuyasreglas ó son de la forma a) β1Aβ2→β1αβ2 (o menos compleja), donde α≠λ ; ó b) θ→α (o menos compleja), donde |θ| ≤ |α| .
Lenguajes Estructurados por Frases (o Recursivamente Enumerables,o Tipo 0, o Lgs0) a aquellos que pueden definirse utilizando Gramáticas Estructuradas por Frases, cuyas reglas son de la forma θ→ α (o menos compleja), donde θ≠λ.
Dentro de estos Lgs0 se encuentra la importantísima clase los Lenguajes Decidibles (o Recursivos,o Lgsdec), que son aquellos para los que es posible construir programas (por ejemplo compiladores) que siempre terminan y anuncian si la cadena sí es elemento del lenguaje o si no lo es (aunque para ello consuman cantidades considerables de tiempo y memoria). Las reglas con las que se definen tienen la misma forma que los Lgs0.
Podemos ver a los Lgs0 como lenguajes semi-decidibles: los programas que los procesan (por ejemplo compiladores) pueden determinar cuando las cadenas sí son elementos del lenguaje, pero cuando no es así continúan su procesamiento indefinidamente.
Lenguajes Generales (o Lgsgral) a aquellos que incluyen a todos los anteriores y a los que no son susceptibles de ser definidos con reglas.
En esta jerarquía ocurre (obviando algunas precisiones) que Lgs3⊂≠ Lgs2⊂≠ Lgs1⊂≠ Lgsdec⊂≠ Lgs0 ⊂≠ Lgsgrals.
Esto enuncia con mayor exactitud lo que mencionamos sobre la cantidad de programas (|N|) y de lenguajes (|2N|): de todo el universo de lenguajes Lgsgrals, solamente para los Lgsdecpodemos escribir procesadores que determinan cuando las cadenas sí forman parte del lenguaje y también cuando no es así.
Ejemplos de especificaciones usando gramáticas
Especifiquemos ahora con gramáticas los lenguajes que definimos “algebraicamente” en el número anterior:
L1 : am bn cidk , para m, n, i, k ≥ 0 e independientes entre sí:
E → λ | a E | b | b F | c | c G | d | d H
F → b | b F | c | c G | d | d H
G → c | c G | d | d H
H → d | d H
Como pueden observar, se trata de una Gramática Regular.
Escribamos lo que se denomina una derivación para a2 b3 c1 d0 :
E → a E → aa E → aa F → aab F → aabb F → aabbb F → aabbb G → aabbbc G → aabbbc H → aabbbc λ → aabbbc
Este tipo de gramáticas son equivalentes a las conocidas expresiones regulares, y como veremos en seguida, son suficientes para especificar los “scanners” de los compiladores, los cuales se encargan del análisis lexicográfico.
L2 : am bi ci dm , para m, i ≥ 0 que aparecen por pares y están “anidadas”:
E → a E d | F
F → b F c | λ
Este es un ejemplo “clásico” de una Gramática Libre de Contexto.
He aquí una derivación para a2 b3 c3 d2 :
E → a E d → aa E dd → aa F dd → aab F cdd → aabb F ccdd → aabbb F cccdd → aabbb λ cccdd
→ aabbbcccdd
(Si hacemos a = ( , b = { , c = } , y d = ) tenemos el caso concreto que mencionamos en la revista anterior.)
Este tipo de gramáticas son equivalentes a los conocidos grafos de sintaxis, y son suficientes para especificar los parsers de los compiladores, los cuales se encargan del análisis sintáctico.
L3 : am bi cm di , para m, i ≥ 0 , que aparecen por pares pero no están anidadas:
S → V | λ
V → a V Y | a c | X
X → b X Z | b Z
Z Y → Z T1 , Z T1 → Y T1 , Y T1 → Y Z /* Reglas que abreviaremos como Z Y → Y Z */
b Y → b c
c Y → c c
c Z → c d
d Z → d d
b Z → b d
Excepto por el λ en la primera regla, que es indispensable porque el lenguaje genera λ, y que es aceptable porque solo la genera el Símbolo-inicial, la anterior es una Gramática Sensible al Contexto: en las 3 primeras reglas no hay contexto (β1= λ y β2= λ, volviéndolas Libres de Contexto); en las restantes ocurre que β1= λ o que β2= λ .
He aquí una derivación para a3 b2 c3 d2 :
S → V → a V Y → a a V Y Y → a a a V Y Y Y
→ a a a X Y Y Y → a a a b X Z Y Y Y → a a a b b Z Z Y Y Y
→ a a a b b Z Y Z Y Y → a a a b b Y Z Z Y Y → a a a b b Y Z Y Z Y → a a a b b Y Y Z Z Y
→ a a a b b Y Y Z Y Z → a a a b b Y Y Y Z Z → a a a b b c Y Y Z Z → a a a b b c c Y Z Z
→ a a a b b c c c Z Z → a a a b b c c c d Z → a a a b b c c c d d
Con este tipo de gramáticas se podrían especificar (al menos buena parte de) los Sistemas de Tipos de los lenguajes de programación, los cuales definen sus aspectos semánticos (de significado, como los del paso de parámetros que mencionamos, o la equivalencia de tipos). Sin embargo, dado que el procesamiento de estas gramáticas es más complejo y costoso en tiempo que el de las Libres de Contexto, y que la mayoría de los constructos de los lenguajes de computación son de este último tipo, los aspectos semánticos también se suelen abordar apoyándose en gramáticas Libres de Contexto y en una Tabla de Identificadores (en la cual suele almacenarse, entre otras cosas, su nombre, clase (si es variable, procedimiento, función, etc.), tipo (v.gr. integer, string, 〈char, real〉→ boolean), y dirección).
Lenguajes y Compiladores
Obviando algunas precisiones, un compilador suele tener una estructura como la siguiente:
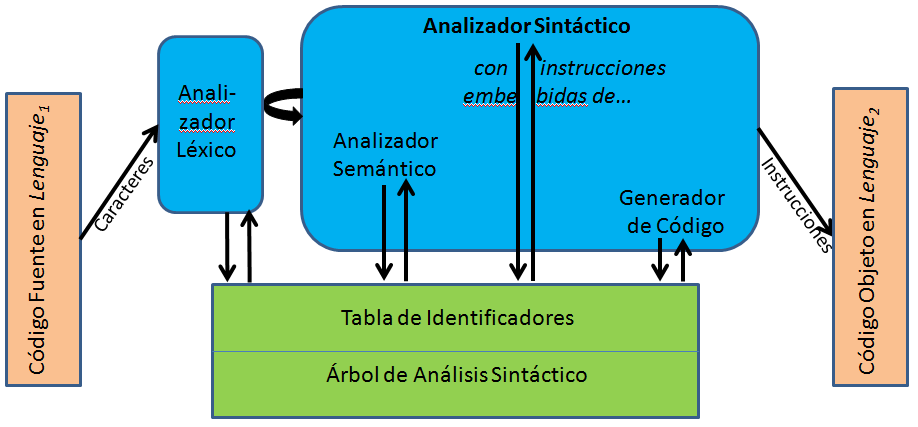
Grosso modo, su funcionamiento es como sigue:
Cada vez que el scanner (Analizador Léxico) es llamado, reanuda su lectura de caracteres del Código Fuente escrito en el Lenguaje1; se salta caracteres irrelevantes (como una secuencia de comentarios, blancos, y/o saltos de línea) y luego concatena los que sí son relevantes hasta completar una cadena que tenga significado por sí misma (por ejemplo “{“, “main” y “contador” en el lenguaje C); en seguida detecta si la cadena es una palabra reservada (como “main”), un símbolo (como “{“,) o un identificador (como “contador”), en cuyo caso lo busca en la Tabla de Identificadores y si no lo encuentra lo da de alta; finalmente, regresa esta información a la subrutina que lo llamó, usualmente el parser.
El parser (Analizador Sintáctico) suele ser el componente central del procesamiento de un compilador. Manda llamar al scanner, el cual le regresa la cadena que acaba de completar y la información que mencionamos arriba. Con esos datos, el parser busca seguir alguna de las reglas gramaticales del lenguaje; en caso de no encontrar alguna envía un mensaje de error. En su procesamiento va utilizando y actualizando la Tabla de Identificadores (por ejemplo, escribiendo si el Identificador es el nombre de una subrutina o de una variable, así como su tipo), va construyendo el Árbol Sintáctico del programa en cuestión (ver un ejemplo en seguida), y va ejecutando instrucciones que tiene “embebidas”, tanto del Analizador Semántico que revisa cuestiones relacionadas principalmente con tipos de datos (para lo cual se apoya en la Tabla de Identificadores), como del Generador de Código (el cual también se apoya en esa Tabla) para ir construyendo el Código Objeto con instrucciones en el Lenguaje2.
El árbol sintáctico para la cadena a2 b3 c3 d2 del lenguaje L2, descrito arriba, se muestra en la siguiente figura. En ella se puede observar que se parte de S0 y se van generando ramificaciones sustituyendo no-Terminales mediante la aplicación de alguna regla de la gramática; las hojas del árbol acaban siendo Terminales o λ.

Compiladores y Arquitectura
La investigación en Arquitectura de Software ha estado motivada principalmente porque los sistemas han venido creciendo en tamaño y complejidad, haciendo que el tema de mayor preocupación no sean ya tanto los algoritmos y las estructuras de datos, sino la interacción entre los constituyentes del sistema.
Esta investigación puede verse como una continuación natural del desarrollo de mecanismos de abstracción en los lenguajes de programación, los cuales buscan facilitar el desarrollo de sistemas:
Los primeros programas de software fueron escritos en lenguaje máquina. La inserción de una nueva instrucción podía requerir tener que revisar manualmente el programa completo, lo cual motivó el desarrollo de Ensambladores Simbólicos, que hacían actualización automática de referencias y permitían utilizar nemónicos en lugar de códigos de operación de instrucciones. Los posteriores procesadores de macros fueron más allá y permitieron que un solo símbolo fuera sustituido por una secuencia de instrucciones.
Después se detectaron patrones de ejecución comunes, como la evaluación de expresiones aritmético-algebraicas, el llamado a subrutinas, así como las instrucciones de alternación (como el “if”) y de repetición (como el “while”).
Luego se detectaron también patrones en el uso de datos, que condujeron al desarrollo de Sistema de Tipos que incluían tipos básicos y constructores de tipos.
Después vino la introducción de módulos, que permitió “aislar” subrutinas y tipos de datos para impedir su modificación, y proveer interfaces de los mismos solamente para su uso a (el resto de) los programadores.
Hoy se trabaja en la formalización de Patrones Arquitectónicos para poder procesarlos con lenguajes formales, facilitando la construcción de la arquitectura los sistemas.
Es común que la arquitectura de un producto de software se defina formalmente como un grafo dirigido definido por: a) un conjunto (finito) de nodos, que son los componentes del producto (subrutinas, datos, etc.); b) un conjunto (finito) de conectores entre los nodos (interacciones como llamadas, accesos a datos, etc.); y (eventualmente) c) un conjunto de restricciones e invariantes sobre los grafos (v.gr. la ausencia de ciclos).
En la literatura especializada se han documentado varios patrones arquitectónicos. Dos de ellos son:
Pipelines: en ellos los componentes son programas que llamamos filters y que se ejecutan secuencialmente, y los conectores, que llamamos pipes, son los flujos de datos entre ellos.
Inicialmente (en los 70’s), la arquitectura de un compilador se veía como un pipeline:

Repositories: uno de los tipos más importantes de repository son los blackboards, en los cuales hay una(s) estructura(s) de datos central(es) a la(s) que se conectan los componentes, la(s) cual(es) dirige(n) la ejecución de los mismos.
La arquitectura de los compiladores se ha venido sofisticando y hoy en día tiene más bien una estructura de blackboard como la que mostramos al inicio de la sección anterior.
Los compiladores pueden ser un muy buen ejemplo al abordar el tema de los patrones arquitectónicos:
facilitan el estudio de la necesidad y aplicabilidad de patrones a la luz de la complejidad y sofisticación el producto en cuestión a lo largo del tiempo (como hemos intentado hacerlo aquí, si bien superficialmente);
cuando se construyen compiladores se aprovechan los avances en el procesamiento de lenguajes formales para generar automáticamente el blackboard y utilizar meta-lenguajes especializados (como como las Expresiones Regulares, la notación BNF, y los Grafos de Sintaxis) con los cuales se especifica la instancia del compilador específico, así como para aplicar el método de análisis sintáctico que resulte más conveniente.
Podremos abundar sobre este tema en números posteriores.
Luis Vinicio León Carrillo es Director General y co-fundador de e-Quallity. Fue profesor-investigador en la universidad ITESO. Realizó estudios de posgrado en Alemania, durante los cuales abordó temas relacionados con la prueba de software y los métodos y lenguajes formales.
- Log in to post comments