Publicado en
A lo largo de las entregas anteriores de esta columna, hemos estado revisando varias cosas alrededor de lenguajes: lenguajes naturales (lingüística computacional), lenguajes formales, computer languages (de especificación, de documentación, etcétera), paradigmas y generaciones de lenguajes de programación, y componentes de un compilador.
Revisamos la Jerarquía de Chomsky, que se enfoca en la estructura de los lenguajes, razón por la cual se usa para definir la sintaxis de lenguajes formales.
Vamos a hacer una breve digresión en este número para platicarles con un poco más de profundidad sobre el tema que mencionamos en nuestra reseña de actividad durante la reunión interina del ISO/IEC JTC1/SC7.
La sintaxis de un lenguaje —que como dijimos se refiere a su estructura— es un aspecto muy importante del mismo, y se utiliza ampliamente en el desarrollo de compiladores.
La “semántica formal” —que se refiere al significado de un lenguaje—, es muy importante también porque agrega precisión a la definición del lenguaje, pero actualmente no es tan común que se utilice en la construcción de compiladores, lo cual puede conducir a que por ejemplo un programa dado a 2 compiladores diferentes para el mismo lenguaje tenga comportamientos distintos.
La semántica define el significado de un lenguaje a partir de los constructos del lenguaje, y con ello también el de los programas escritos en él. Existen varios enfoques para hacerlo; entre los más importantes se encuentran:
-
Operacional: se especifica la semántica proporcionando el código fuente de un intérprete que define el comportamiento de los programas de ese lenguaje. Este enfoque, al ser tan operativo, no permite razonar sobre el lenguaje (mediante mecanismos lógico-matemáticos).
-
Axiomático: la semántica se especifica definiendo una “teoría matemática” para el lenguaje con la cual se puedan probar propiedades de programas escritos en ese lenguaje. El énfasis no está en lo que significa el lenguaje, sino en lo que puede probarse acerca de él.
-
Denotacional: se especifica la semántica asociando a cada constructo del lenguaje un conjunto de funciones matemáticas que definen los significados denotando conjuntos. La semántica está dada en términos de conjuntos, funciones, relaciones, tuplas, y predicados, así como operaciones sobre ell@s. Este enfoque tiene un nivel de abstracción aún mayor al del enfoque Axiomático.
Las “teorías matemáticas” mencionadas arriba se refieren a sistemas lógicos que constan de:
-
Reglas sintácticas para construir fórmulas bien formadas;
-
Axiomas, que son fórmulas que se consideran “verdaderas”; y
-
Reglas de inferencia, que permiten partir de los axiomas y generar nuevas fórmulas “verdaderas”, que suelen ser llamadas teoremas.
Algunos de los sistemas lógicos más conocidos y utilizados en las ciencias de la computación son el cálculo proposicional, y el cálculo de predicados de primer orden.
Estos sistemas lógicos son algo realmente extraordinario (y muchos de ellos fueron desarrollados en los años 30 del siglo pasado, antes de la Jerarquía de Chomsky), que facilitan el razonamiento semi-automático y el descubrimiento de “verdades lógicas” acerca de programas, por ejemplo.
Pero la semántica formal no solo se ha utilizado para especificar el significado de lenguajes, sino también de productos de software, entre otras cosas.
Como se mencionó en la reseña de la Reunión de la ISO, uno de los temas que se abordó en el Working Group fue el Model Based Testing. En la siguiente sección vamos a vincular ese tema con lo visto aquí sobre semántica formal.
Model Based Testing (MBT)
El ser humano ha creado modelos desde hace muchísimo tiempo. Algunos de ellos han resultado ser erróneos (como el de la teoría geocéntrica), otros “simplistas” (como el de la teoría heliocéntrica con círculos representando las órbitas de los planetas), y otros tan cercanos a la realidad que permiten predecir acontecimientos y situaciones con mucha exactitud (como el de la teoría heliocéntrica con elipses describiendo las órbitas de los planetas y apoyado en el formalismo del cálculo infinitesimal).
Dependiendo del grado de formalidad y del nivel de abstracción de los modelos, de ellos se puede generar, entre otras cosas: el software mismo, su documentación, o conjuntos de casos de prueba.
En general, la complejidad de los mecanismos de refinamiento y el nivel de detalle que se requieren para hacer documentación basada en modelos o testing basado en modelos suelen ser menores que el requerido para hacer desarrollo dirigido por modelos, porque de manera general se requiere menos para definir qué debe hacer un producto de software que para definir cómo debe hacerlo.
Por otro lado, el nivel de formalización del modelo determina lo que se puede hacer de manera automática, y la formalización la hacemos precisamente con lenguajes formales —en nuestros ejemplos, el formalismo del cálculo infinitesimal es el que permite realizar cálculos complejos con precisión.
Hay una buena cantidad de lenguajes para definir modelos. Podemos clasificarlos considerando qué tan formal es su definición: algunos de ellos son informales (como los lenguajes naturales), otros son semi-formales (como los diagramas de UML), y otros formales (como las máquinas de estados finitos, Larch, Clear, Z y B AMN).
Los lenguajes de modelado formales, que son los que más nos interesan, podríamos a la vez clasificarlos de acuerdo a su enfoque teórico en dos grandes categorías:
Orientados a Modelos como Z, en el cual se especifica el producto en términos de conjuntos, funciones, relaciones, tuplas, predicados, etcétera, y se hace razonamiento sobre modelos utilizando el cálculo de predicados de primer orden —notarán semejanzas con la semántica denotacional descrita arriba.
Orientados a Propiedades, los cuales suelen dividirse en dos categorías:
-
Axiomáticos como Larch, en el cual se especifican precondiciones y poscondiciones que describen el comportamiento de cada operación del producto utilizando cálculo predicados de primer orden —notarán semejanzas con la Semántica Axiomática descrita arriba.
-
Algebraicos como Clear, en el que los axiomas sólo pueden tener la forma de ecuaciones.
Obviando los procesos de soporte, y en el marco del proceso de prueba de software organizacional, si partimos de un modelo especificado en un lenguaje de modelado formal como los que acabamos de describir brevemente, se podría aplicar MBT como se muestra en la figura 1.
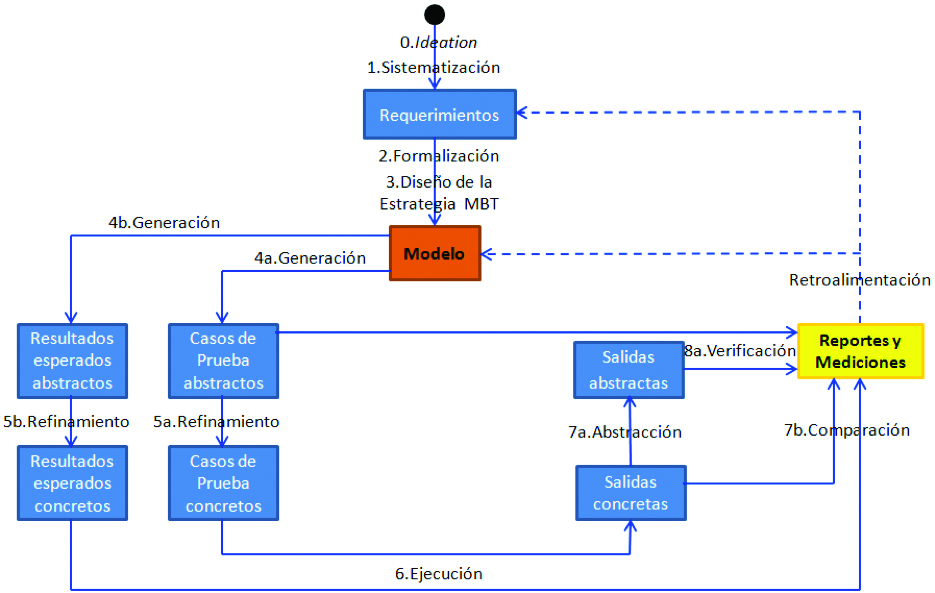
Figura 1. Model Based Testing
La siguiente llave explica el flujo:
0. Ideation: ideas acerca de lo que debe hacer el producto de software.
1. Sistematización de la información anterior, con lo cual se genera el documento de requerimientos.
2. Formalización de los Requerimientos utilizando el lenguaje de modelado.
3. Diseño de la Estrategia para MBT considerando contexto, alcance, objetivos y riesgos asociados al producto, así como criterios de terminación para las pruebas.
4a. Generación de casos de prueba abstractos (es decir, descritos en el lenguaje de modelado). Eventualmente se realiza en este paso también una minimización y secuenciación de los casos de prueba.
5a. Refinamiento de los casos de prueba abstractos para obtener casos de prueba concretos, los cuales podrán estar descritos en un lenguaje natural o en un scripting lenguaje para automatizar las pruebas.
6. Ejecución del producto de software a probar, aplicándole los casos de prueba concretos obtenidos.
7a. Abstracción de las salidas concretas generadas durante la ejecución, transformándolas en salidas abstractas (es decir, descritos en el lenguaje de modelado).
8a. Verificación: usando el modelo como Oráculo, reemplazar cada caso de prueba abstracto y su correspondiente salida abstracta en el modelo; si se reduce a Verdadero, significa que no se detectaron errores; si se reduce a Falso, entonces sí se detectaron. Generar reportes conteniendo esa información y las mediciones que se hayan definido en el Diseño de la Estrategia para MBT.
Y si el modelo se analiza durante la Generación de casos de prueba abstractos, se abre también la posibilidad de ejecutar las siguientes actividades:
4b. Generación de resultados esperados abstractos (descritos en el lenguaje de modelado).
5b. Refinamiento de los casos de prueba abstractos para obtener resultados esperados concretos.
6. Ejecución del producto de software a probar.
7b. Comparación del resultado esperado concreto con la respectiva salida concreta: si no son iguales, significa que sí se detectaron errores; si son iguales, entonces NO fueron detectados. Generar reportes conteniendo esa información y las mediciones que se hayan definido en el diseño de la estrategia para MBT. Utilizar la información generada como retroalimentación para eventualmente mejorar o corregir el modelo y/o los requerimientos.
Utilizar modelos escritos en un lenguaje formal de modelado puede tener un gran alcance. Si se cuenta con mecanismos para refinar el modelo y con suficiente información sobre cómo el producto debe hacer las cosas (y no sólo qué cosas debe hacer), entonces podríamos estar hablando de un Método Formal, con el cual podríamos refinar un modelo para obtener un diseño de alto nivel, luego refinar ese diseño y dejar que el método genere el código asociado.
Luis Vinicio León Carrillo es Director General de e-Quallity. Realizó estudios de posgrado en Alemania, durante los cuales abordó temas relacionados con la Prueba de software y los Métodos y Lenguajes Formales. Fue profesor-investigador en la universidad ITESO y cofundador del Capítulo Occidente de la AMCIS. Es miembro de la Delegación Mexicana ante la ISO.
Aarón Moreno Monroy es Director de Tecnología de e-Quallity. Fue profesor de asignatura den la Universidad ITESO. Estudió la Maestría en Ciencias en el CINVESTAV; su trabajo de tesis tuvo que ver con verificación formal, que aborda la prueba de software utilizando modelos matemáticos. Es miembro de la Delegación Mexicana ante la ISO.
- Log in to post comments