Conociendo el DMBOK
Autor
Sección
Publicado en
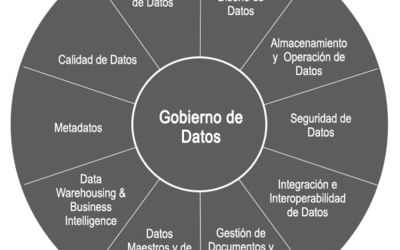
Para desarrollar o mejorar una cultura de gestión de datos e información no es necesario reinventar la rueda, podemos apoyarnos en el Data Management Body of Knowledge.
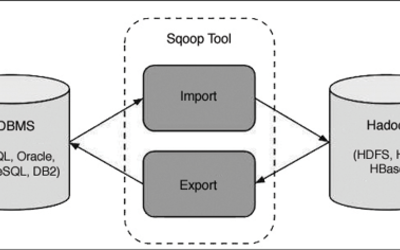
El manejo de información masiva se ha hecho cotidiano, y una estrategia común para analizar grandes cantidades de datos es moverla de las bases de datos relacionales tradicionales (RDBMS) hacia bases de datos columnares distribuidas.
Al iniciar un proyecto de Data Science se tienen que tomar diversas decisiones para que cada etapa del flujo de trabajo o pipeline cumpla con las metas especificadas. El pipeline que definamos depende de factores tales como la experiencia que se tiene con las plataformas, herramientas, lenguajes o algoritmos específicos así como de la investigación previa y referencias externas.
Hace ya varios años que se me dio la oportunidad de publicar mi primer artículo, en la revista Software Guru número 28 y el gusto por escribir no me ha dejado desde esa época.
En el año 2012, las empresas en general contaban con la suficiente capacidad de base de datos para manejar y procesar la actividad diaria de sus clientes; sin embargo, analistas de IDC han pronosticado un incremento masivo en el uso de Internet móvil en los teléfonos inteligentes y tabletas.
El procesamiento de datos es una de las actividades más arduas a la que nos enfrentamos al desarrollar sistemas transaccionales, especialmente cuando se afectan grandes cantidades de datos. Por medio de procedimientos almacenados, o stored procedures (SP), el sistema de base de datos es capaz de ejecutar un conjunto de instrucciones bien coordinadas entre sí que afectan la información con el fin de lograr un objetivo dentro del sistema.